
AIML Level-2 Report
30 / 12 / 2024
Lekha DH
5th Sem ISE
Task 1 - Decision Tree based ID3 Algorithm
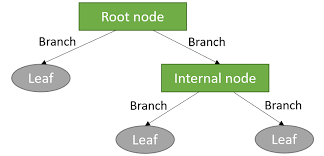
A decision tree, which has a hierarchical structure made up of root, branches, internal, and leaf nodes, is a non-parametric supervised learning approach used for classification and regression applications.
Decision Tree Terminologies:
1.Root Node
2.Decision Node
3.Leaf Node
4.Sub-tree
5.Pruning
6.Parent and Child Node
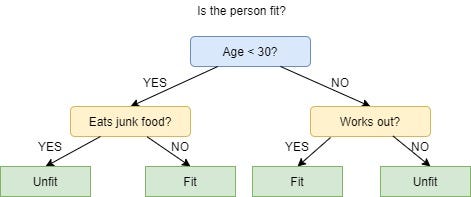
ID3 Algorithm:
ID3 stands for Iterative Dichotomiser 3 and is named such because the algorithm iteratively (repeatedly) dichotomizes(divides) features into two or more groups at each step. ID3 Algorithm
Task 2 - Naive Bayesian Classifier
A Naive Bayes classifier is a probabilistic machine learning model that’s used for classification task. The crux of the classifier is based on the Bayes theorem.
Bayes Theorem:
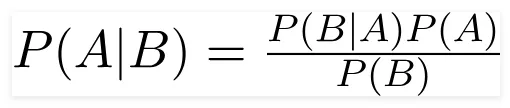
Task 3 - Ensemble techniques
Ensemble learning is a general meta approach to machine learning that seeks better predictive performance by combining the predictions from multiple models.
The three main classes of ensemble learning methods are bagging, stacking, and boosting, and it is important to both have a detailed understanding of each method and to consider them on your predictive modeling project.
Ensemble techniques on the Titanic Dataset:
Task 4 - Random Forest, GBM and Xgboost
Random Forest
• Definition:
Random Forest is an ensemble learning technique that combines multiple decision trees to improve accuracy and reduce overfitting.
• Working Principle:
It creates multiple trees using random subsets of data and features, and the final prediction is based on majority voting (for classification) or averaging (for regression).
• Advantages:
Handles large datasets efficiently.
Reduces overfitting by averaging predictions.
Performs well with missing data.
• Limitations:
Can be computationally expensive for large datasets.
Difficult to interpret compared to a single decision tree.
• Use Cases:
Image classification, fraud detection, medical diagnosis.
GBM
• Definition:
GBM is a boosting algorithm that builds models sequentially, where each new model corrects the errors of the previous one.
• Working Principle:
It minimizes the loss function using gradient descent, improving model accuracy over iterations.
• Advantages:
High accuracy with minimal tuning.
Handles both categorical and numerical data.
Effective in reducing bias.
• Limitations:
Can be slow due to sequential training.
Prone to overfitting without proper regularization.
• Use Cases:
Risk modeling, sales forecasting, click-through rate prediction.
XGBoost (Extreme Gradient Boosting)
• Definition:
XGBoost is an advanced implementation of gradient boosting designed for speed and performance optimization.
• Working Principle:
It uses a parallel tree boosting technique, applies regularization, and employs early stopping to prevent overfitting.
• Advantages:
Highly efficient and scalable for large datasets.
Offers built-in regularization (L1 & L2).
Supports distributed computing.
• Limitations:
Requires parameter tuning for optimal results.
Can be resource-intensive.
• Use Cases:
Recommendation systems, financial modeling, time series forecasting.
Task 5 - Hyperparameter Tuning
###• Definition: Hyperparameters are configuration settings that control the training process of machine learning models.
• Difference from Parameters:
Unlike model parameters (e.g., weights and biases), hyperparameters are set before training begins.
• Examples:
Common hyperparameters include learning rate, batch size, number of epochs, and number of hidden layers.
• Purpose:
They influence the model’s learning behavior and overall performance.
• Tuning Methods:
Techniques like grid search and random search are often used for hyperparameter optimization.
• Impact:
Proper tuning of hyperparameters can significantly enhance the model’s accuracy and effectiveness.
Task 6 : Image Classification using KMeans Clustering
1. Understanding K Means Clustering:
K-Means Clustering is an unsupervised machine learning algorithm used to group data into K clusters based on similarity. It works by initializing random centroids, assigning data points to the nearest centroid, and updating the centroids until convergence. The goal is to minimize the within-cluster sum of squares (WCSS). It's widely used in customer segmentation, image compression, and pattern recognition.
2. Classify a set of images into a given number of categories using KMeans Clustering using MNIST dataset
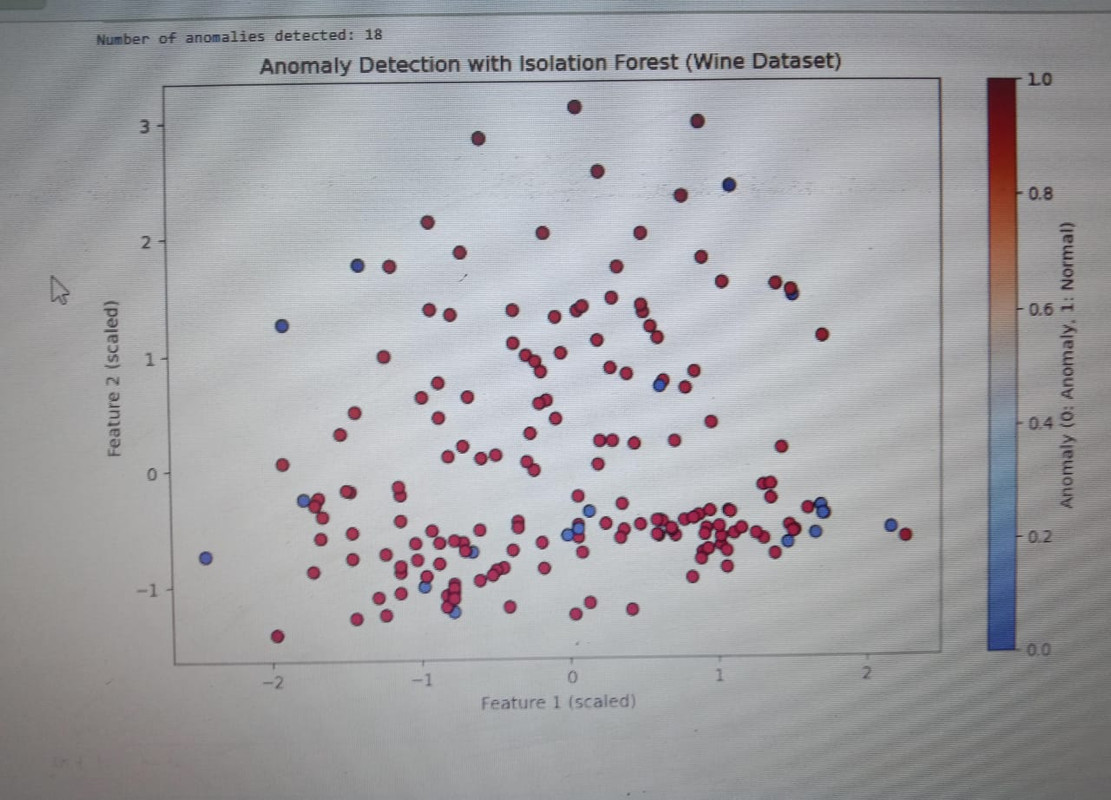
Task 7-Anomaly Detection
Anomaly Detection is the technique of identifying rare events or observations which can raise suspicions by being statistically different from the rest of the observations.
Task 8: Generative AI Task Using GAN
● Definition: GAN (Generative Adversarial Network) is a type of artificial neural network used to generate realistic data by training two models — a generator and a discriminator.
● Generator: Creates synthetic data that mimics real data. It tries to fool the discriminator.
● Discriminator: Evaluates data and distinguishes between real and fake data. It helps the generator improve over time.
● Training Process: Both models compete with each other in a zero-sum game, improving their performance iteratively.
● Applications: GANs are widely used in image generation, video synthesis, text-to-image conversion, and deepfake creation.
● Evaluation Metrics: Metrics like FID (Fréchet Inception Distance) and IS (Inception Score) are used to assess the quality of generated data.
● Challenges: GANs often suffer from mode collapse, where the generator produces limited variations of data, and training can be unstable.
● Advancements: Variants like CycleGAN, StyleGAN, and BigGAN are developed to overcome traditional GAN limitations.

Task 9: PDF Query Using LangChain
• Definition:
• LangChain is a framework designed for building applications that leverage large language models (LLMs) to process and analyze data, including PDF documents.
• Purpose:
• To extract relevant information from PDF documents based on user queries using natural language understanding (NLU).
• Key Features:
• Supports PDF parsing and text extraction. • Understands and interprets user queries. • Retrieves specific sections or information from documents. • Provides conversational or search-based query results.
• Components Involved:
• LangChain: For query interpretation and processing. • PDF Parser: For extracting text from PDF files (e.g., PyMuPDF, PDFMiner). • LLM (Large Language Model): For understanding and responding to queries.
• Example Workflow:
Upload a PDF document.
User inputs a query.
LangChain extracts and interprets the query.
The system fetches relevant information from the PDF.
Results are displayed to the user.
• Advantages:
• Automates document analysis and data extraction. • Reduces manual effort in searching for information. • Provides accurate and context-aware responses. • Supports large-scale document processing.
• Applications:
• Legal document analysis. • Research paper summarization. • Financial report extraction. • Contract or policy document review.
Task 10: Table Analysis Using PaddleOCR
• Definition:
PaddleOCR is an Optical Character Recognition (OCR) tool used for extracting text from images, especially tables.
• Importance:
Recognizes table structures and extracts text from cells. Supports multi-language recognition. Useful for digitizing documents like invoices, reports, and receipts.
• Advantages of Table Analysis Using PaddleOCR:
Accurate detection of table structures and text. Supports multiple languages. Efficient for large-scale document processing. Easy integration with other Python libraries. Provides structured output (e.g., CSV, JSON).