
Level 2 report
31 / 3 / 2025
Marvel Level 3 Report
Task 1: Decision Tree Based on ID3 Algorithm
A decision tree is a tree-like structure used to make decisions or predictions based on given conditions. It is a machine learning algorithm that can be used for both classification and regression tasks.
Key Learnings:
- Terminologies: Root node, internal nodes, branches, leaf nodes, tree height.
- Reducing impurities: Techniques like Gini Impurity, Information Gain, Entropy, and Mean Squared Error (MSE).
- Overfitting problem: A very deep tree can lead to overfitting, reducing prediction accuracy.
- Pruning: A method to remove less important branches to improve generalization.
- Splitting criteria: Algorithms such as ID3, C4.5, and CART help decide the optimal order of features.
ID3 Algorithm:
-
ID3 (Iterative Dichotomiser 3) uses entropy and information gain to build a decision tree.
-
At each branching stage, the split with the highest information gain is selected.
-
Notes


Code Implementation: GitHub Repository
Task 2: Naïve Bayesian Classifier
The Naïve Bayes classifier is a probabilistic machine learning model used for classification tasks. It is based on Bayes' Theorem and assumes that all features are independent, which is often an unrealistic assumption, hence the term "Naïve."
Key Learnings:
- Despite its assumptions, Naïve Bayes is highly effective for tasks like text classification and spam detection.
- Types of Naïve Bayes:
- Gaussian Naïve Bayes (for continuous data)
- Multinomial Naïve Bayes (for text classification)
- Bernoulli Naïve Bayes (for binary features)
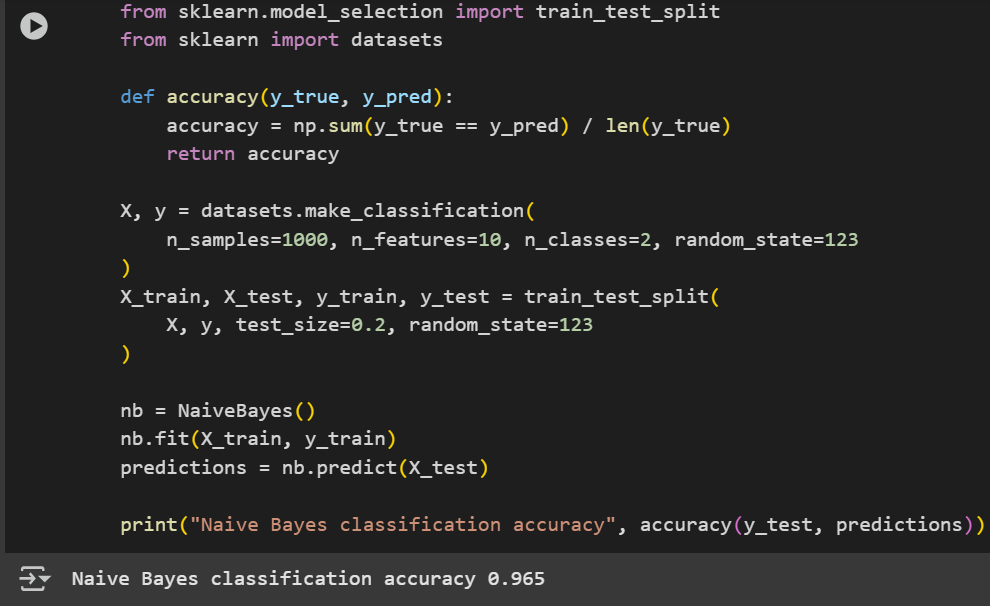 Code Implementation: Naïve Bayes from scratch
Code Implementation: Naïve Bayes from scratch
Task 3: Anomaly Detection
Anomaly detection involves identifying deviations from expected or normal data patterns.
Types of Anomalies:
- Point Anomaly: A single data point deviates significantly from the rest.
- Contextual Anomaly: An anomaly that depends on the context (e.g., seasonal sales spikes).
- Collective Anomaly: A group of points that together form an anomaly.
Key Learnings:
- Used KNN clustering to find anomalies in the data.
- Plotted contour plots to visualize anomalies.
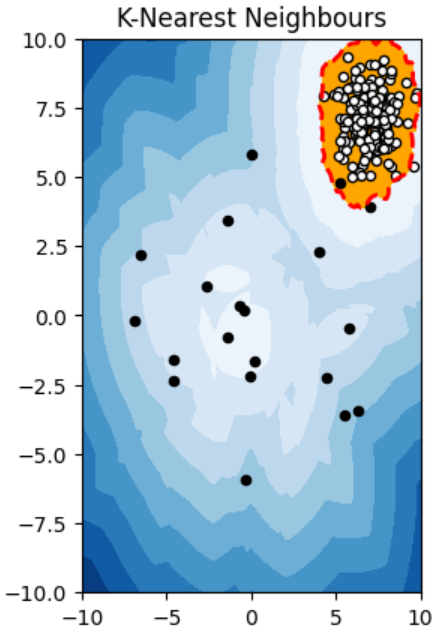
- Implemented different algorithms to detect anomalies.
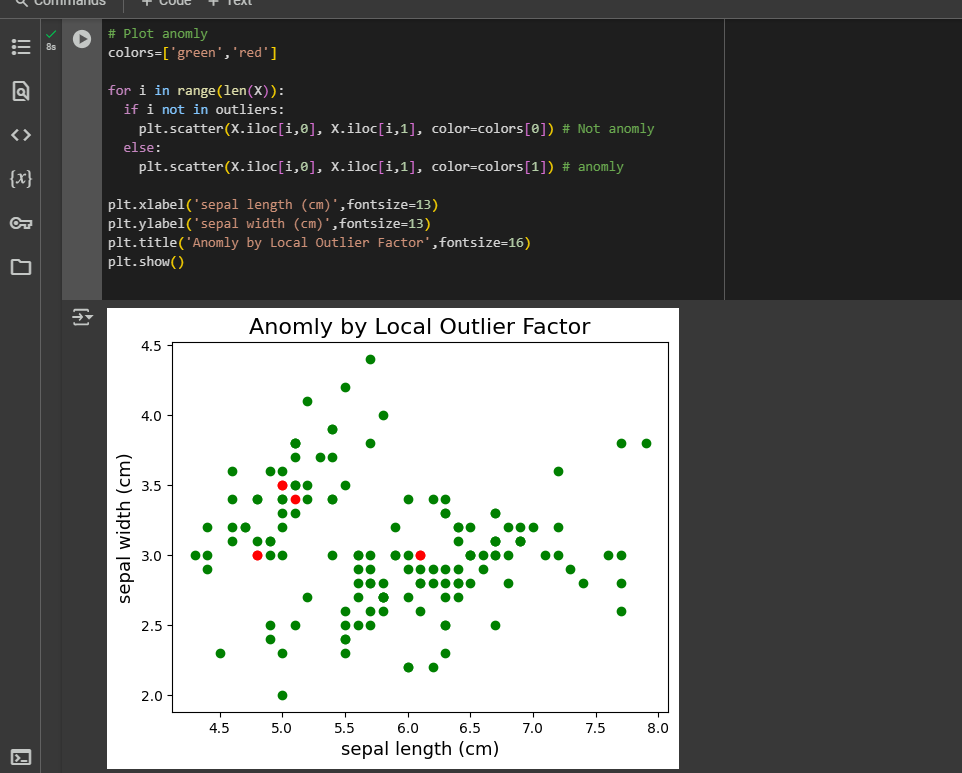
-Code Implementation: Finding Anomalie
-Code Implementation: Implementing anomaly detecting algorithms
Task 4: Ensemble Techniques
Ensemble learning is a technique that combines multiple models to improve predictive performance by reducing errors, overfitting, and variance.
Types of Ensemble Techniques:
-
Bagging (Bootstrap Aggregating)
- Multiple models (bags) are trained on different subsets of data.
- The average prediction is used for final decision-making.
-
Boosting (AdaBoost)
- Incorrectly classified instances are given higher weights in the next model iteration.
- Helps improve weak classifiers iteratively.
-
Stacking
- Combines predictions from multiple models into a new model for improved accuracy.
-
Voting & Averaging
- Uses multiple models and aggregates their predictions.
- Hard Voting: The class predicted by the majority is chosen.
- Soft Voting: Averages the predicted probabilities for classification.
-Code Implementation: Bagging, Voting and Boosting
-Code Implementation: Stacking
Task 5: KMeans Clustering
KMeans is an unsupervised learning algorithm used for clustering data into K groups.
Steps:
- Choose K and initialize centroids.
- Assign data points to nearest centroid.
- Recalculate centroids.
- Repeat until convergence.
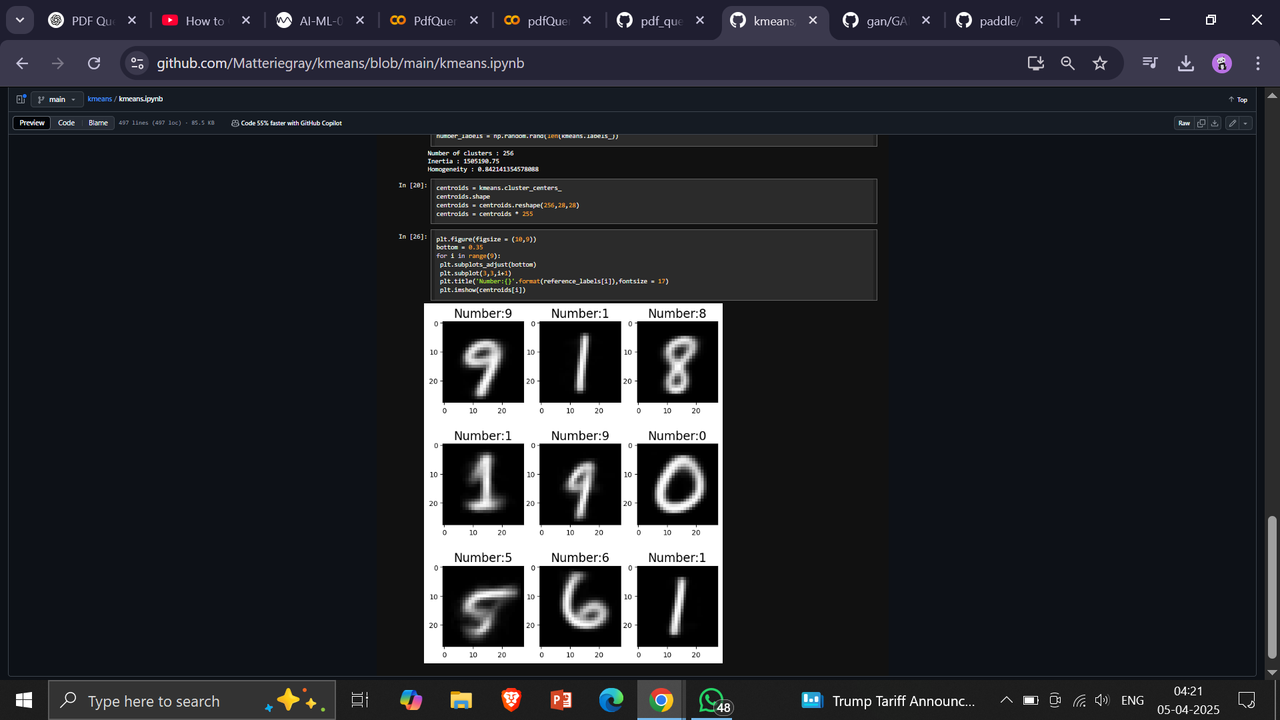
-Code Implementation: Code
Task 6: Generative AI Task Using GAN
GAN (Generative Adversarial Network) is a model with two networks:
- Generator: creates fake data
- Discriminator: distinguishes between real and fake data
They compete against each other until the discriminator can’t tell real from fake.
-Code Implementation: Code
Task 7: PDF Query Using LangChain
LangChain is an open-source framework for building apps using LLMs (Large Language Models).
I used it to parse a budget PDF file and query specific information using:
- PDF parsing techniques
- LLM-powered question answering
-Code Implementation: Code
Task 8: PaddleOCR
PaddleOCR is an open-source Optical Character Recognition tool that supports:
- Text detection & recognition
- Multiple languages
- Lightweight and fast integration
I used it to extract text from a photo of a bill.
-Code Implementation: Code
Task 9: Random Forest, GBM, and XGBoost
Random Forest
- A bagging ensemble of decision trees.
- Uses majority voting for prediction.

GBM (Gradient Boosting Machine)
- A boosting technique where each tree learns to correct errors from the previous tree.
- Uses loss minimization, often with MSE.


XGBoost
- An optimized version of GBM.
- Includes:
- Regularization
- Parallel processing
- Missing value handling
- Tree pruning
-Code Implementation: Code
##Task 10: Hyperparameter Tuning
Hyperparameter tuning is the process of selecting the best set of hyperparameters (not learned from data) for model training.
Techniques:
- GridSearchCV
- RandomSearchCV
- Bayesian Optimization
-Code Implementation: Code