
Sohan Aiyappa's AIML Level 2 Report
27 / 9 / 2024
Task 1 : Decision Tree Based ID3 Algorithm
The ID3 algorithm is a decision tree algorithm that helps classify data by selecting the attribute that provides the highest information gain at each step. This means it splits the dataset based on the attribute that best separates the different classes, aiming to reduce uncertainty or entropy.
For this task, I built and evaluated a decision tree model using the ID3 algorithm. First, I developed functions to measure the entropy in the data and to determine the best attributes for splitting based on their information gain. I then created a class to encapsulate the ID3 algorithm, including methods for training the model, making predictions, and evaluating its performance.

Using the PlayTennis dataset, which includes various weather conditions and other factors to classify whether tennis will be played or not, I trained and tested the model.After training, the model achieved an accuracy of 100% on the test dataset.
Decision Tree-ID3

Task 2 : Naive Bayesian Classifier
Naive Bayes classifier is a simple, probabilistic machine learning algorithm based on Bayes' theorem. It assumes that features are independent given the class label, which simplifies calculations. It's commonly used for text classification, spam detection, and sentiment analysis due to its efficiency and effectiveness with large datasets.
Bayes' Theorem calculates the probability of a class based on prior knowledge of conditions related to the class. The Naive Bayes classifier assumes that the features are independent of each other.
For this task, I built and evaluated a Multinomial Naive Bayes classifier to predict whether to play golf based on weather conditions.
I encoded the categorical data into numerical values and separated the features from the target variable . I then implemented functions to calculate prior probabilities of each class, the likelihood of feature values given the class, and posterior probabilities for predictions. Using these, I built the classifier and applied it to the test data.
After evaluating the model, I achieved an accuracy of 50%.I am a bit disappointed with this result , I seek to improve it"s accuracy while working on the hyperparameter tuning task.
Naive Bayesian Classifier

Task 3 : Random Forest , GBM and Xgboost
Random Forest is an ensemble learning method that constructs multiple decision trees during training and merges their outputs for classification or regression tasks. By averaging the predictions of various trees, it reduces overfitting and improves accuracy. It's robust to noise and effective for handling large datasets with diverse features.
For this task, I built and evaluated a Random Forest classifier using the Iris dataset. The dataset includes measurements of iris flowers, categorized into three species. First, I loaded the Iris dataset and split it into training and test sets, with 70% of the data used for training and 30% for testing. I used the RandomForestClassifier from scikit-learn, setting the number of trees (estimators) to 100.
After training the model on the training set, I used it to predict the species of the flowers in the test set. The model's accuracy was evaluated using the accuracy metric, achieving an accuracy of 100%.

XGBoost
XGBoost (Extreme Gradient Boosting) is an optimized implementation of gradient boosting that is specifically designed for speed and performance.

I built an XGBoost model using the Wine Quality dataset to predict wine quality based on various chemical properties. First, I loaded the dataset and split it into training and testing sets. Then, I used the XGBClassifier from the XGBoost library to create my model. After training it on the data, I made predictions on the test set and calculated the accuracy to see how well it performed.

GBM
Gradient Boosting Machine (GBM) is an ensemble learning technique used for regression and classification tasks. It builds models sequentially, where each new model corrects the errors made by the previous ones.

I built a GBM model using the Breast Cancer Wisconsin dataset to classify tumors as malignant or benign. After loading the dataset, I split it into training and testing sets. I used GradientBoostingClassifier from sklearn to create the model, and trained it on the data. Once trained, I made predictions on the test set and calculated the accuracy to see how well the model performed.

Task 4 : Ensemble Techniques
Ensemble techniques combine multiple models to improve overall performance and robustness. They work on the principle that aggregating predictions from various models can lead to better accuracy than any single model alone. Common methods include bagging (e.g., Random Forest), boosting (e.g., AdaBoost, Gradient Boosting), and stacking. These techniques can reduce variance, bias, or improve predictions by leveraging the strengths of different algorithms.
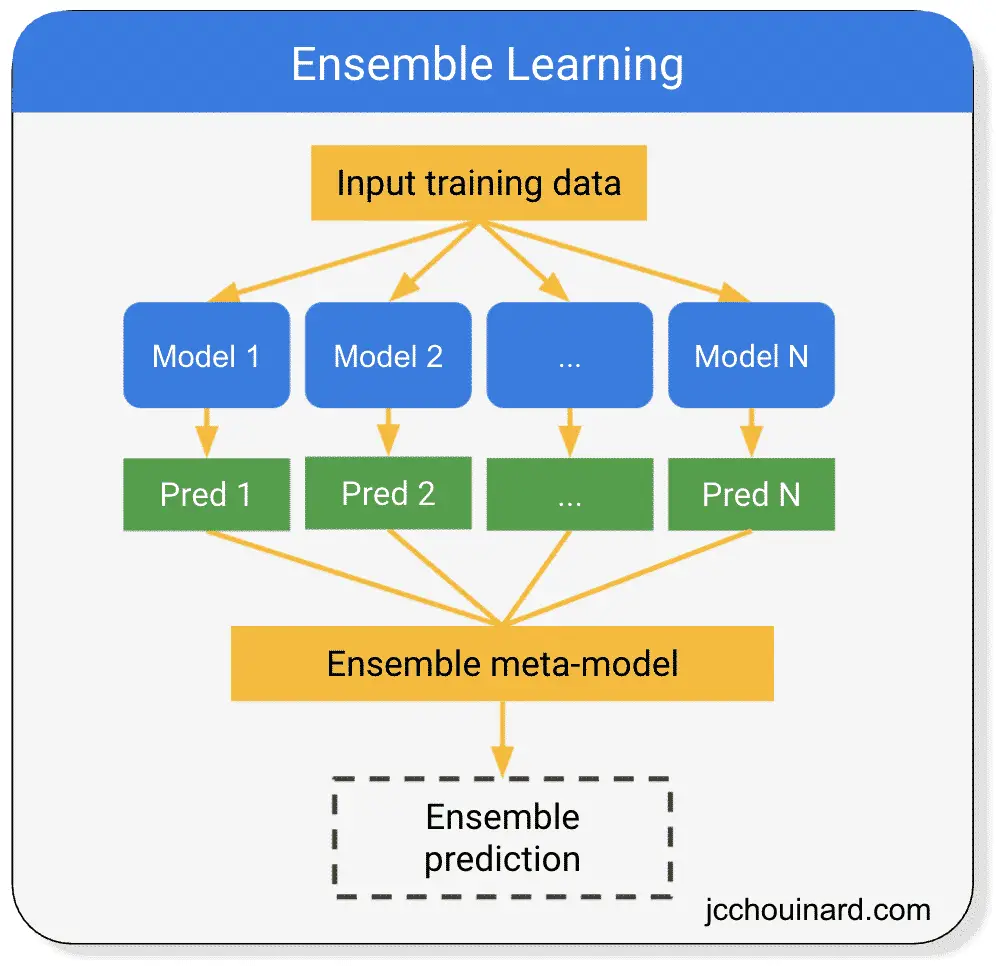
I utilized a VotingClassifier from scikit-learn to predict survival on the Titanic dataset. The ensemble model combined predictions from RandomForestClassifier and LogisticRegression, achieving an accuracy of approximately 81% on the test set. This has been my favourite task so far , as this opened new doors by utlising multiple models to increase predictability by a significant degree.
Ensemble Model

Task 5 : Hyperparameter Tuning
Hyperparameter tuning is the process of optimizing the parameters that govern the training of a machine learning model, known as hyperparameters. Unlike model parameters, which are learned during training, hyperparameters are set before the training process begins and can significantly influence the model's performance.
In my project, I focused on hyperparameter tuning for a Naive Bayes classifier designed to predict whether to play golf based on weather conditions. After preparing the dataset and encoding categorical variables, I implemented functions to calculate prior probabilities and likelihoods with Laplace smoothing. I utilized K-Fold cross-validation to evaluate the model's performance across different values of the smoothing parameter, exploring a range of alpha values (0.1 to 2)
Hyperparameter Tuning

Task 6 : K Means Clustering
K-means clustering is an unsupervised learning algorithm used to partition a dataset into k distinct clusters based on feature similarity. The algorithm assigns data points to the nearest cluster centroid, iteratively updating the centroids until convergence. This method is useful for identifying patterns and groupings in data.
.png)
In my project, I implemented K-Means clustering on the MNIST dataset to group handwritten digits into clusters. After loading and preprocessing the data, I reshaped the images into a flat format and normalized the pixel values. I specified the number of clusters as 10, corresponding to the digits 0-9, and applied the KMeans algorithm to fit the data. I evaluated the clustering performance using several metrics. Then , I visualized the cluster centers by plotting the average images of each cluster.
k means clustering

Task 7 : Anomaly Detection
Anomaly detection involves identifying data points that deviate significantly from the expected pattern in a dataset. It is crucial for applications like fraud detection, network security, and fault detection, as it helps in spotting unusual behavior or outliers that could indicate errors, fraud, or other significant events.
I used Support Vector Machines (SVM) for anomaly detection in my project, employing a one-class SVM approach.

In this task , I created a system to detect unusual data points using a One-Class Support Vector Machine (SVM). I began by generating a dataset with a main cluster of points and added some random outliers to represent anomalies. After training the model to recognize normal data, I used it to identify which points were considered anomalies. Lastly , I visualized the results, showing normal data in blue and the detected anomalies in purple.
anomaly detection

Task 8 : Generative AI :
A GAN, or Generative Adversarial Network, has two parts: a Generator that creates fake images and a Discriminator that tries to tell if an image is real or fake. The Generator's goal is to make images that are so realistic, the Discriminator can’t tell them apart from real ones. As the two networks compete, the Generator gets better at creating lifelike images, while the Discriminator improves at spotting the fakes. Over time, this back-and-forth helps the Generator produce more realistic images.

For this project, I built a Generative Adversarial Network (GAN) using PyTorch to generate images from the CIFAR-10 dataset, which contains 32x32 color images. I designed both the Generator and Discriminator using convolutional layers and trained them using the Adam optimizer. To speed up the process, I used a GPU in Google Colab. However, I encountered a limitation: Colab can only handle up to 7 training epochs before running into runtime issues. Because of this constraint, the images produced by the GAN are still blurry, as the model hasn't had enough time to learn the fine details necessary for generating clearer images.
The GAN Model

Task 9 : PDF query using Langchain
LangChain is a tool that helps you build smart applications using language models like GPT. It makes it easier to connect these models to tasks like processing documents, answering questions, or pulling data from different sources. It’s flexible and helps with anything from chatbots to automating text analysis.
In this project, I built a LangChain model in Google Colab, where I integrated Google Drive to access and process a PDF file. The model reads and prints the entire content of the PDF, offering a simple way to view it within the notebook. I then created custom functions that allow for dynamic interaction with the text. One function can delete any specified line, another calculates how many times a particular word appears, and the final function extracts relevant sections based on specific keywords. This setup makes it easy to analyze and manipulate the document's content based on user needs.
The Langchain Model

Task 10 : Table Analysis using PaddleOCR
PaddleOCR is an open-source Optical Character Recognition (OCR) toolkit developed by PaddlePaddle. It includes features like text detection, character recognition, and layout analysis, making it suitable for a wide range of applications, including document digitization, data extraction from images, and scene text recognition.
I developed a pipeline using PaddleOCR to extract and analyze tabular data from images. The process involved preprocessing images to enhance table visibility, utilizing PaddleOCR for text detection and extraction, and structuring the data into a Pandas DataFrame and printing it . Finally, I performed statistical analysis( calculate word occurence , delete specified line) and made a function to extract and print relevant text based on keyword(input), demonstrating an effective approach to automate the extraction and analysis of tabular data from images.

The PaddleOCR model
This level was comparitively hard , but there was so much that I learnt. Thank You!