1 / 4 / 2025
Level 2 Aiml Report
02/04/2025
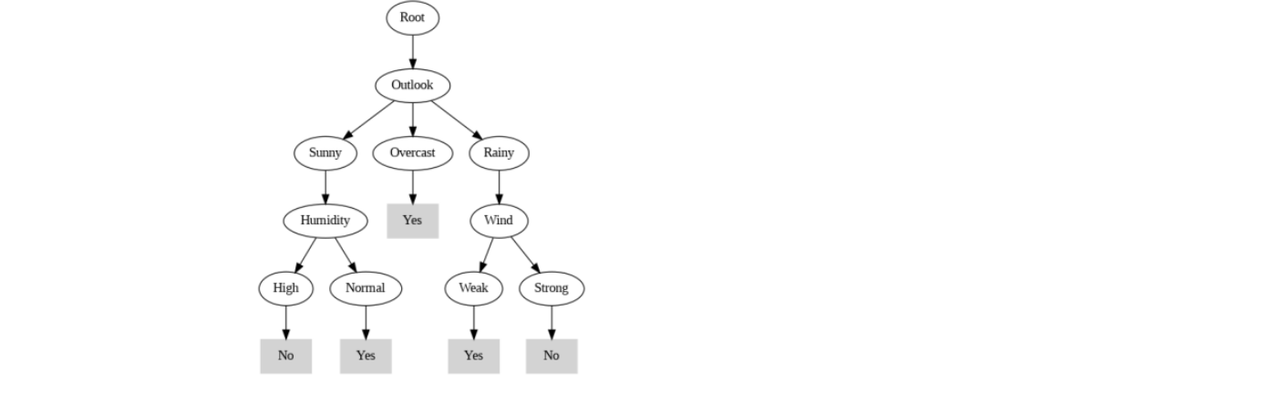
Task 1:Decision Tree based ID3 Algorithm
The main objective of this task was to understand the ID3 decision tree algorithm, including its basic terminology, working principles, and entropy-based splitting. Then, implement ID3 from scratch in Python to classify data effectively.
The ID3 algorithm is a widely used decision tree classifier that employs a top-down, greedy approach to construct a decision tree by selecting attributes based on the concept of information gain. This method is effective for classification tasks, allowing for clear interpretability of decision-making processes.Click here
Task 2:Naive Bayesian Classifier
The objective of this task was to understand the Naive Bayes classifier, its probabilistic foundations, and how it works with real-world datasets. Then, implement it from scratch and using sklearn for text classification and other applications.
The Naive Bayesian Classifier is a probabilistic model based on Bayes' theorem, which assumes that the features are conditionally independent given the class label. This classifier is particularly useful for text classification tasks, such as spam detection, due to its simplicity and efficiency. Click here
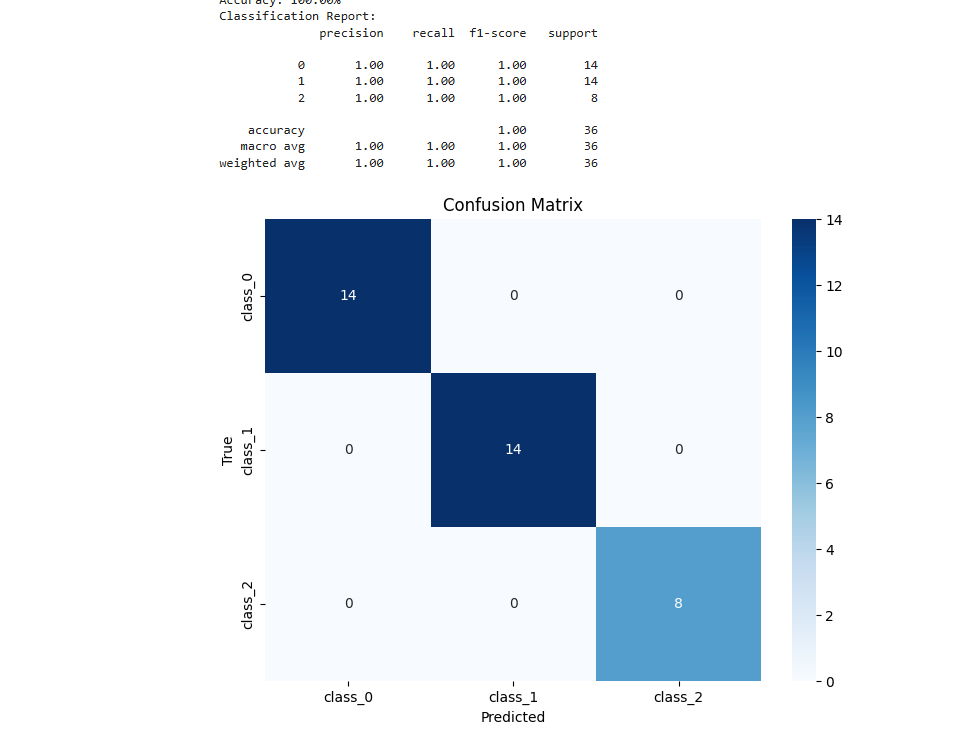
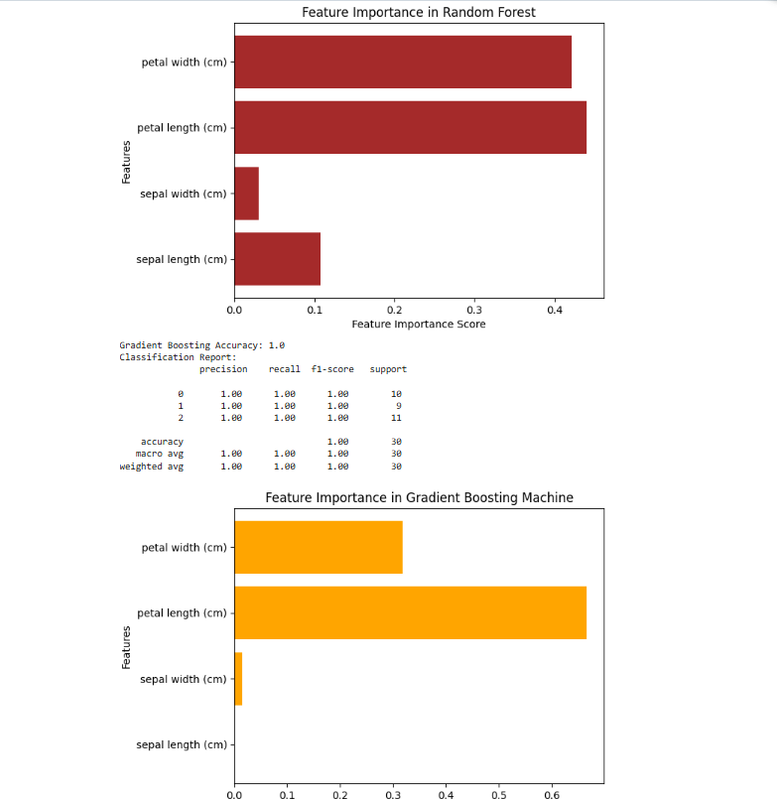
Task 4:Random Forest, GBM and Xgboost
The objective of this task is to understand and implement Random Forest, Gradient Boosting (GBM), and XGBoost algorithms. which included learning about their working principles, advantages, and parameter tuning, followed by hands-on implementation using Python. Click here
Task 5: Hyperparameter Tuning
The objective of this task was to understand hyperparameter tuning and its impact on model performance. Which involves selecting a suitable dataset, training a model, and optimizing its hyperparameters using techniques like Grid Search and Random Search to improve accuracy. Click here
Task 6: Image Classification using KMeans Clustering
The objective of this task was to understand K-Means clustering and its application in image classification. Using the MNIST dataset, the goal was to cluster images into different categories by identifying patterns without supervision.
It is an unsupervised learning algorithm that partitions data into K distinct clusters based on feature similarity. In the context of image classification, KMeans can be applied to group similar images together, facilitating tasks such as pattern recognition and organization of visual data. Click here

Task 9: PDF Query Using LangChain
This task involves extracting and analyzing text from PDF documents by using Python libraries like PyPDF2 and transformers. The goal is to develop a system that can read PDFs, process queries, and generate relevant responses based on the content.
The script mounts Google Drive to access PDF files, installs necessary libraries, and extracts text from the PDF using PyPDF2. A language model (GPT-Neo) is used to process and respond to user queries based on the PDF content. Additional functions allow line deletion, word counting, and section extraction by keyword. The system responds to queries by summarizing relevant sections, providing a quick and efficient way to retrieve information from PDF documents. Click here

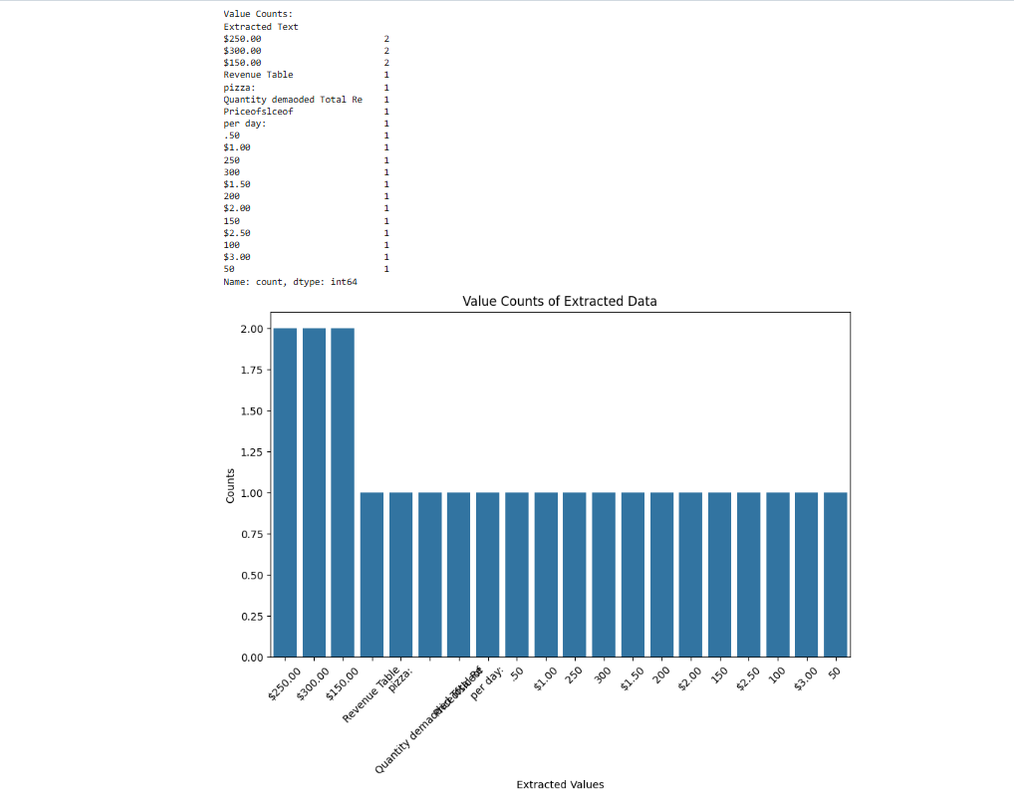
Task 10 : Table Analysis Using PaddleOCR
This task focuses on extracting and analyzing tabular data from images or scanned documents using PaddleOCR, an optical character recognition (OCR) tool. The goal is to detect and extract text, perform data analysis, and visualize the results.
The script loads an image, applies PaddleOCR to extract text, and stores the results in a pandas DataFrame. It calculates summary statistics and counts the frequency of extracted values. The data is visualized using a bar plot to display the distribution of extracted text. This approach is useful for automating the extraction and analysis of tabular data from scanned documents or images. Click here