
LEVEL 3: Report
30 / 3 / 2025
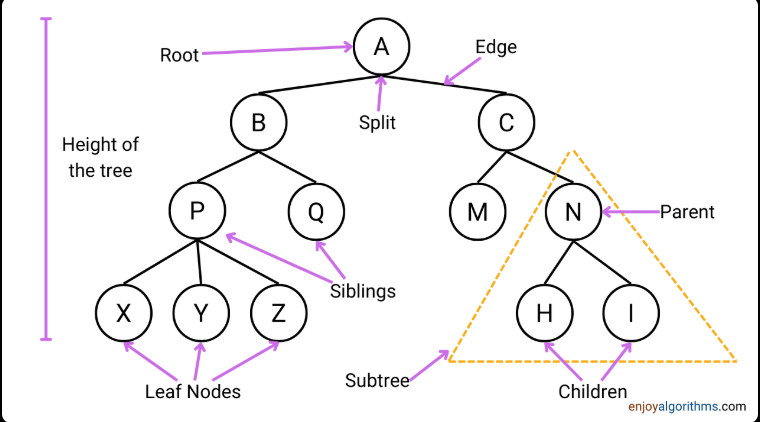
Task1: Decision Tree based ID3 Algorithm
I implemented a Decision Tree using the ID3 algorithm to classify the Iris dataset. The algorithm selects the best feature for splitting based on entropy and information gain. Key features like petal length and petal width played a crucial role in classification. The model effectively differentiated between Setosa, Versicolor, and Virginica species, demonstrating the importance of feature selection in decision trees.
Code : https://github.com/sadhanathanga/Marvel-Level-3.1/blob/main/ID3.ipynb
Task2: Naive Bayesian Classifier
I built a Naive Bayesian Classifier to categorize messages as spam or ham using the spam-ham dataset. The model analyzes word frequency in messages to calculate probabilities and classify them accordingly. Text data was converted into numerical form to make it interpretable for the machine. This helped in detecting spam messages effectively. Code - https://github.com/sadhanathanga/Marvel-Level-3.2/blob/main/naive_bayes.ipynb
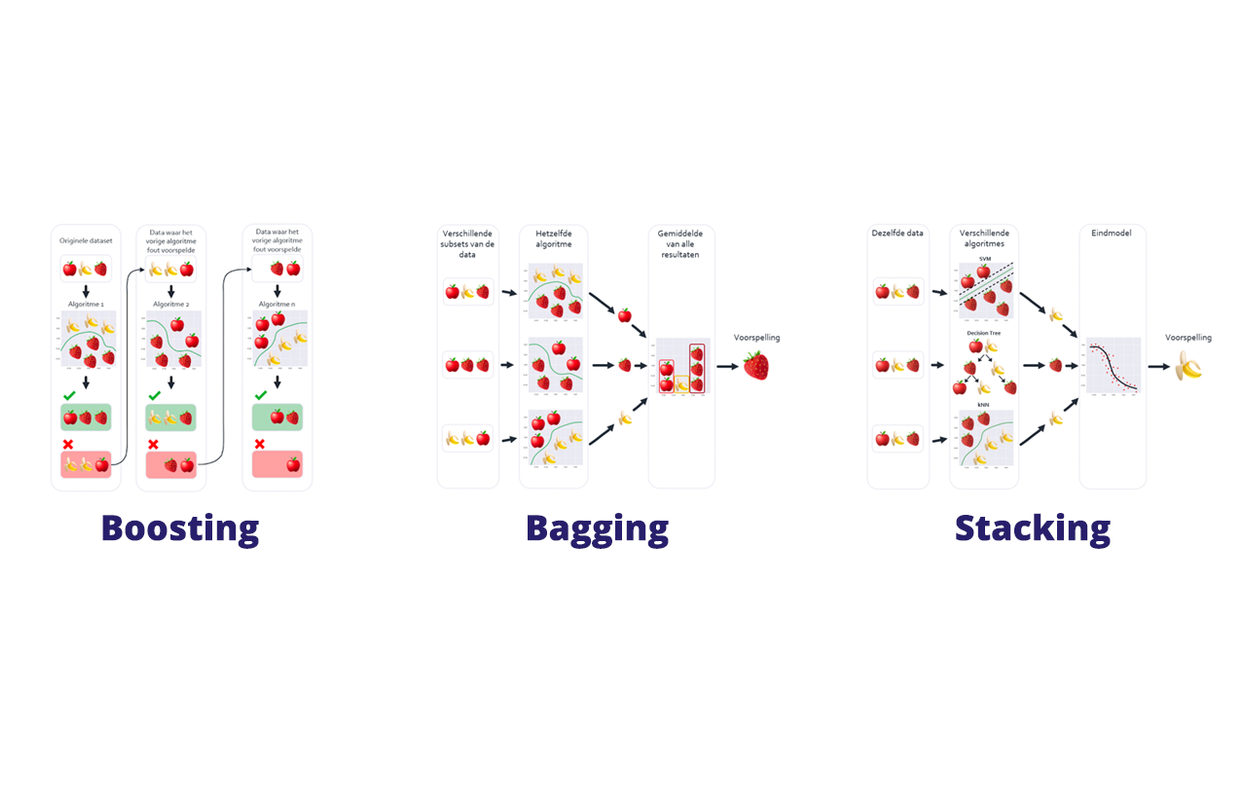
Task3: Ensemble techniques
I applied Ensemble Techniques to the Titanic dataset, using methods like Bagging, Boosting, and Stacking. Models such as Random Forest, Decision Trees, and Gradient Boosting were combined to improve accuracy. Ensemble learning helped enhance prediction performance by leveraging multiple models. This approach led to better generalization on the dataset.
Code - https://github.com/sadhanathanga/Marvel-Level-3.3/blob/main/Ensemble.ipynb
Task 4: Random Forest, GBM and Xgboost
1. Random Forest –
Random Forest Classifiers are a collection of individual decision trees that are trained by bagging. Used random forest to predict whether a individual has a heart disease. C ode - https://github.com/sadhanathanga/Marvel-Level-3.4/blob/main/Random_forst.ipynb
2. GBM –
GBM uses Boosting, which is a sequential technique where models are trained repeatedly, which each new model correcting the errors of the previous model. I used GBM on the breast cancer dataset, to predict if a person has breast cancer or not. Code - https://github.com/sadhanathanga/Marvel-Level-3.4/blob/main/GBM.ipynb
3. XGBoost –
XGBoost (Extreme Gradient Boosting) is an optimized machine learning algorithm based on gradient boosting. Used this algorithm on the titanic dataset, to predict if an individual survived the ship wrek. Code - https://github.com/sadhanathanga/Marvel-Level-3.4/blob/main/XGBoost.ipynb
Task 5: Hyperparameter Tuning
I used Hyperparameter Tuning to improve the accuracy of the Iris dataset. By applying Grid Search, I optimized parameters like max_depth, min_samples_split, min_samples_leaf, and criterion to find the best values for each. This systematic approach significantly enhanced model performance, ensuring better classification accuracy.
Code - https://github.com/sadhanathanga/Marvel-Level-3.5/blob/main/hyper-parameter%20tuning.ipynb

Task 6: Image Classification using KMeans Clustering
K-means clustering is a popular unsupervised machine learning algorithm used for partitioning a dataset into a pre-defined number of clusters. K means clustering uses clusters or collections of data and finds ‘k’ number of centroids, by averaging it out, such that k is minimum .
Code - https://github.com/sadhanathanga/Marvel-Level-3.6/blob/main/K_Clusters_image_processing.ipynb

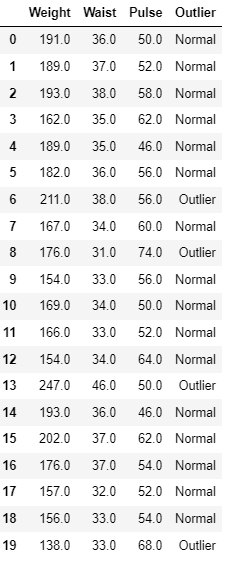
Task 7: Anomaly Detection
Anomaly detection identifies abnormal data points in a stream by analyzing statistical deviations. It can be performed using either supervised or unsupervised learning method.
Code - https://github.com/sadhanathanga/Marvel-Level-3.7/blob/main/Anamoly%20detection.ipynb
Task8: Generative AI Task Using GAN
The CIFAR-10 dataset was successfully loaded and split into training, validation, and test sets. A subset of 30 random images was selected, processed using a sharpening filter, and resized for improved visualization Code - https://github.com/sadhanathanga/Marvel-3.8/blob/main/GAN.ipynb
Task 9: PDF Query Using LangChain
LangChain is a powerful framework that helps developers create agents that can analyze problems and break them into manageable sub-tasks. I worked with libraries such as HuggingFaceEmbeddings, which uses sentence-transformers to produce text embeddings, and the RetrievalQA Chain, which enhances question-answering by combining retrieval with an LLM. Code - https://github.com/sadhanathanga/Marvel-Level-3.9/blob/main/Task_9.ipynb
Task 10: Table Analysis Using PaddleOCR
PaddleOCR is an open-source Optical Character Recognition (OCR) tool developed by PaddlePaddle, a deep learning platform from Baidu. It's a powerful library that supports text detection, recognition, and even layout analysis for a wide range of document types. Code - https://github.com/sadhanathanga/Marvel-Level-3.10/blob/main/paddle.ipynb