
31 / 3 / 2025
Task 1 - Decision Tree based ID3 Algorithm
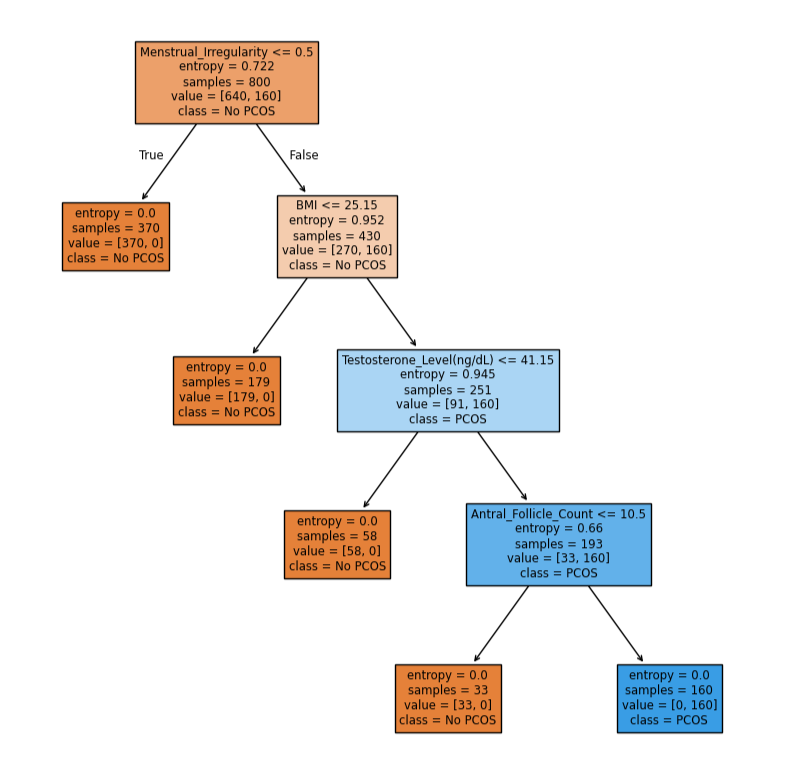
Decision Tree is a supervised learning algorithm used for classification and regression. It splits data into branches based on feature values, making it easy to interpret. when decision tree is used to classify then it’s classification tree while when decision tree is used to predict numerical values then it’s called regression tree. Splitting the data is based on best feature(based on gini impurity or ID3) such that the root nodes are pure nodes while the other nodes are criterias based on which the data is split.
Task 2 - Naive Bayesian Classifier
 Naive Bayes is a supervised classification algorithm based on Bayes' Theorem, assuming feature independence. It calculates the probability of each class and selects the one with the highest probability. for this task, I've used a small custom customer review to categorize it into good and bad reviews using multi-nominal naive bayes classifier. I've got 22% accuracy with both sklearn and from scratch, I've understood that the low accuracy is due to small training and testing set.
Naive Bayes is a supervised classification algorithm based on Bayes' Theorem, assuming feature independence. It calculates the probability of each class and selects the one with the highest probability. for this task, I've used a small custom customer review to categorize it into good and bad reviews using multi-nominal naive bayes classifier. I've got 22% accuracy with both sklearn and from scratch, I've understood that the low accuracy is due to small training and testing set.
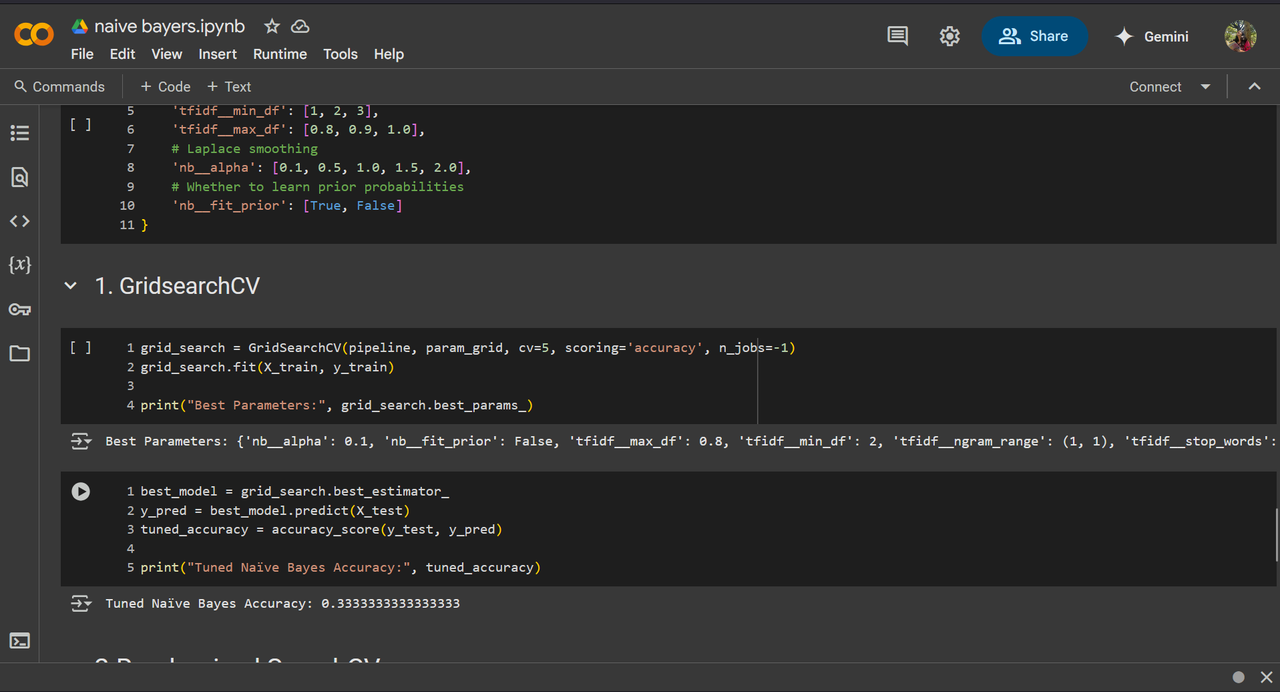
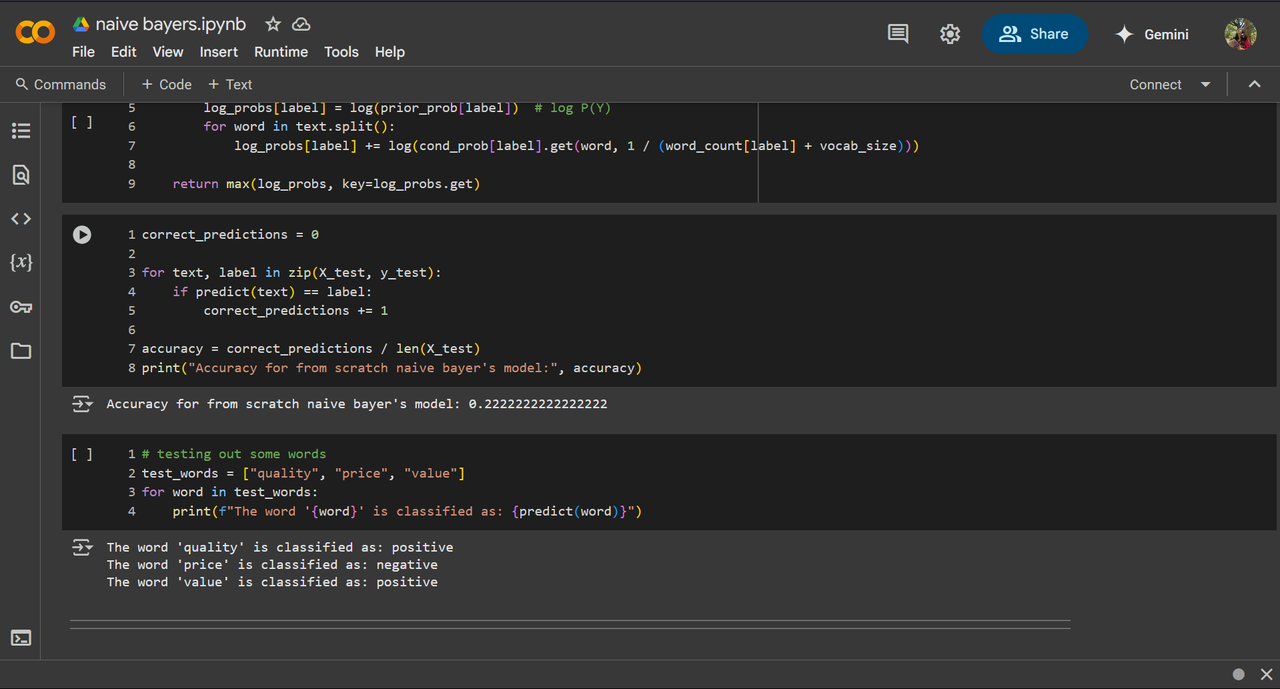 I've performed hyperparameter tuning on this same data.
I've performed hyperparameter tuning on this same data.
Task 3 - Ensemble techniques
Max Voting averaging, weighted avaeraging Ensemble learning is a technique that uses multiple predictions (from different models) and merges them to provide a better results. Ensemble means a collection of. By using this technique, we try to go over the errors provided by a single model.
- we combine outputs of diverse modals to get a precise prediction and resilience against uncertainties i.e like overfitting in some models.
- eg: random forest is an ensemble of decision trees .
- it helps us achieve diversification
ensemble techniques:
-
Max voting
- used for classification problems
- each model’s prediction is a vote and the final prediction is the max vote
- this is more like mode in statistics
-
averaging
- used for probabilities in classification
- used for prediction in regression
- we use average of all prediction
- this is more like mean in statistics
-
Weighted average
- some models are given more importance (based on if the model is accurate) and accordingly their prediction has more weight in the resultant prediction.
-
Rank Averaging
- we assign rank to the models - worst model will be given rank 1 and the best model will be given greater number rank.
- we then assign the weights to the models from the rank i.e model’s rank / sum of all ranks
- multiple each of these weights to their individual models and we sum the results.
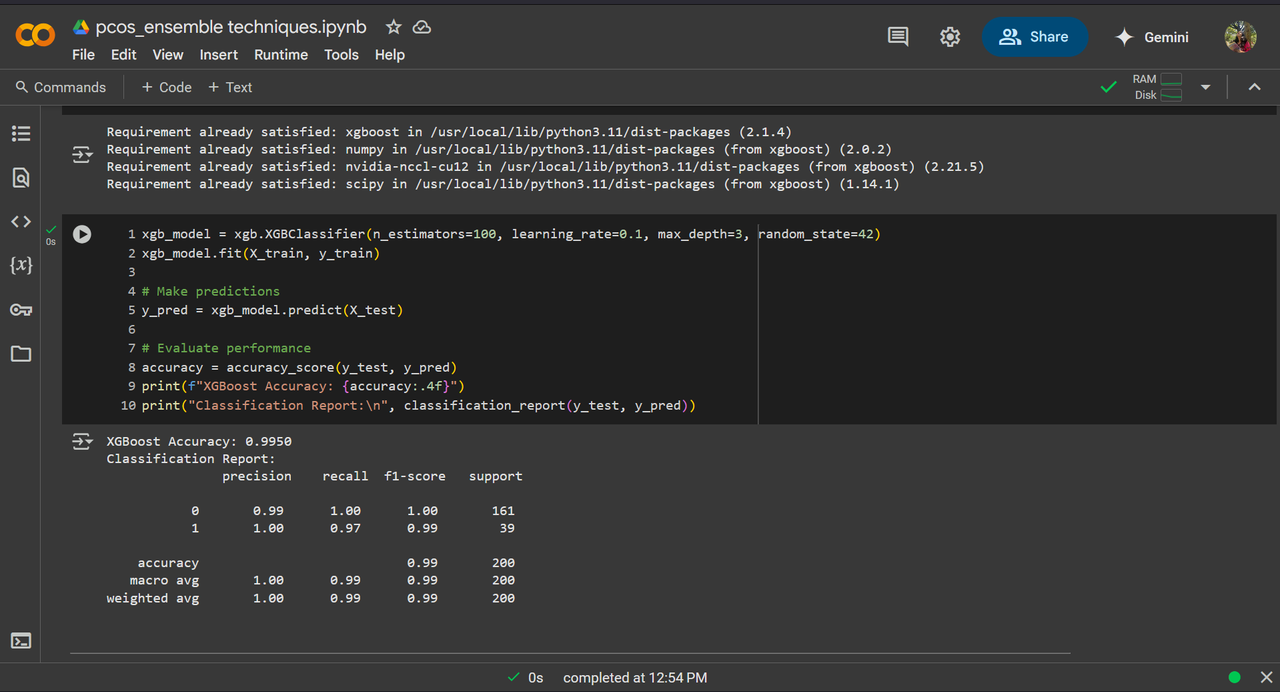
Task 4 - Random Forest, GBM and Xgboost
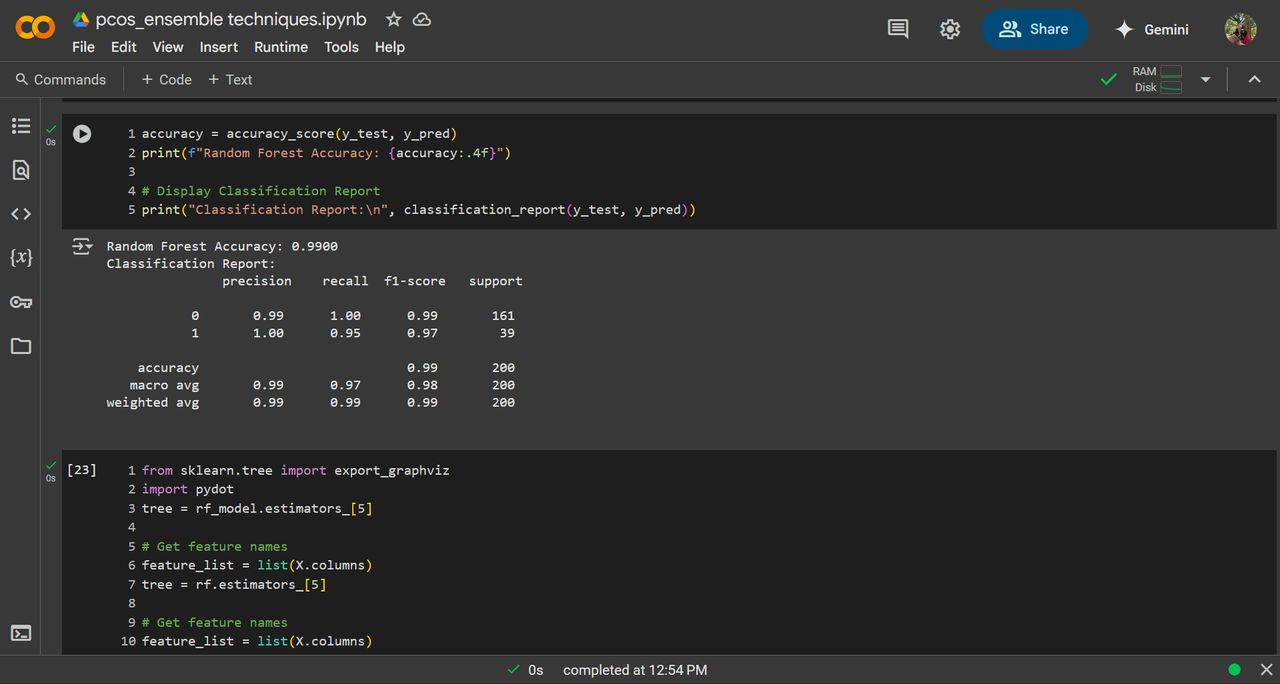
Random Forest, GBM, Xgboost I've used the PCOS dataset from kaggle and performed Random Forest, GBM and Xgboost on it, it gave 99%, 99.5% and 99.5% accuracy respectively.
- Bagging ( Bootstrap Aggregating)
- Random forest
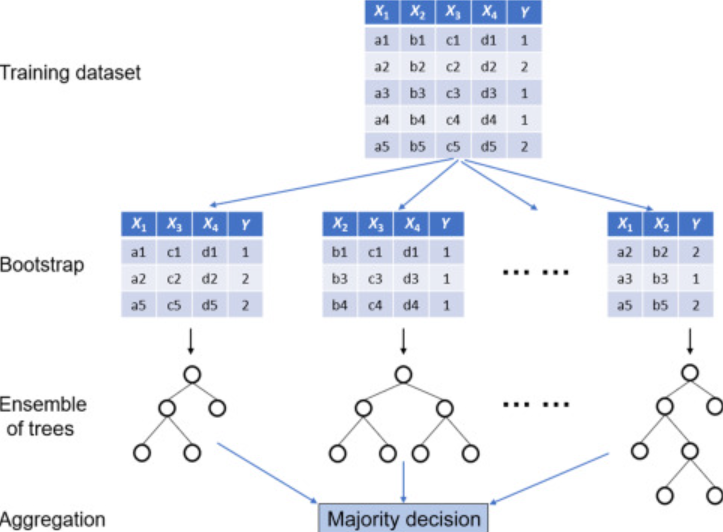 Random Forest is an ensemble learning method that builds multiple decision trees and combines their outputs to improve accuracy and reduce overfitting. Final prediction is based on majority voting from all trees.
Random Forest is an ensemble learning method that builds multiple decision trees and combines their outputs to improve accuracy and reduce overfitting. Final prediction is based on majority voting from all trees.
- boosting Boosting is a sequential process, where each subsequent model attempts to correct the errors of the previous model. The succeeding models are dependent on the previous model.
- GBM
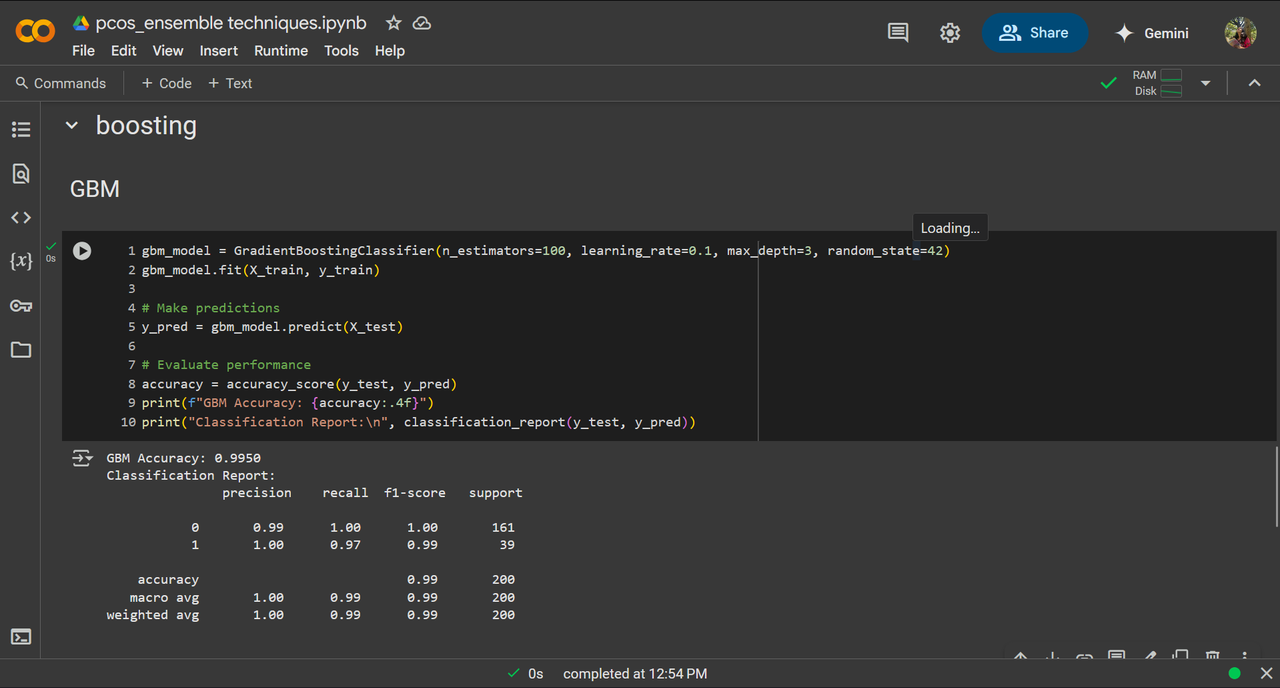
- XGBoost
Task 5 - Hyperparameter Tuning
There are 2 types of parameters - model and hyperparameters. Hyperparameter are the parameters which controls the way the model learns while model paramters are learnt and changed during learning. Hyperparameters are set before training and does not change during the process of learning. eg: Learning Rate (lr) ,Number of Trees (n_estimators),Depth of Trees (max_depth). Hyperparameter tuning is the process of finding the best combination of hyperparameters to improve a machine learning model’s accuracy and efficiency. There are two ways:
- Grid Search: we find the combination of ALL hyperparameters and find the best combination but this is computationally expensive.
- Random Search: it finds the best combination among the random combination of hyperparameters but it might miss the best possible combination.
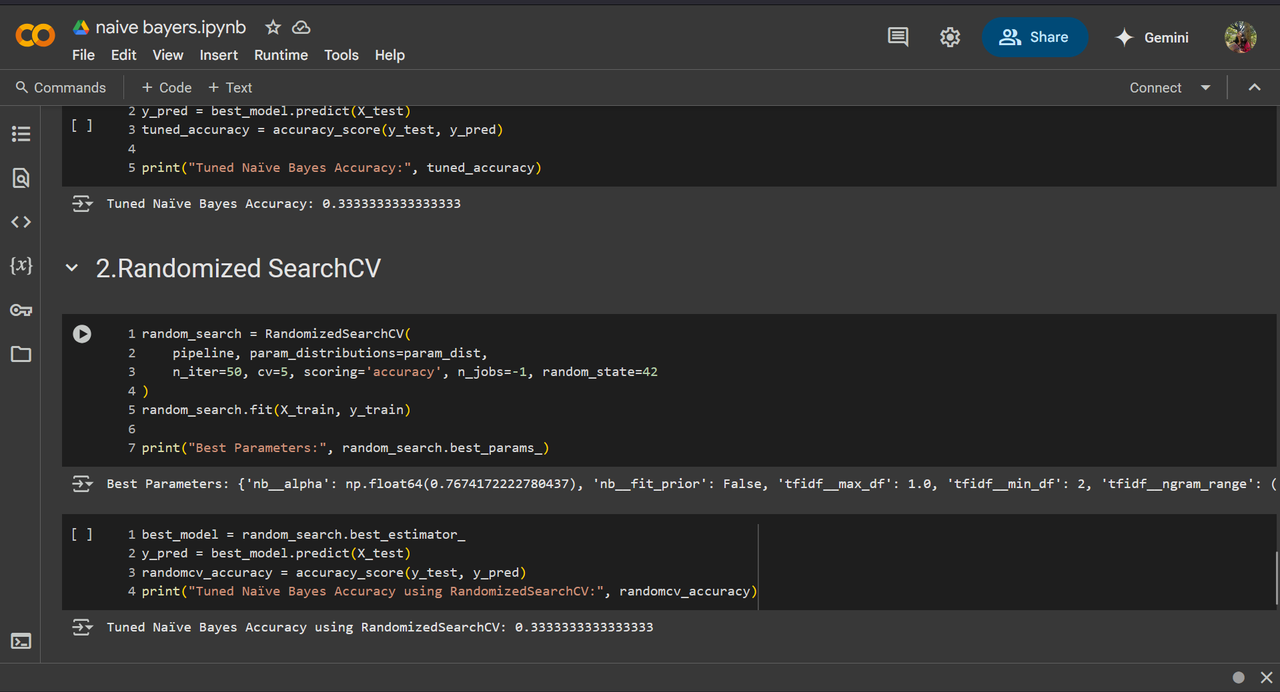 I've got 33% accuracy, previously it was 22% accuracy.
I've got 33% accuracy, previously it was 22% accuracy.
Task 6 : Image Classification using KMeans Clustering
K-means clustering is a technique used to organize data into groups based on their similarity. KMeans clustering randomly selects centroids and assigns each data point to the nearest one, forming clusters. The centroids are then updated as the average position of points in each cluster. This process repeats until centroids stabilize, grouping similar data points together.
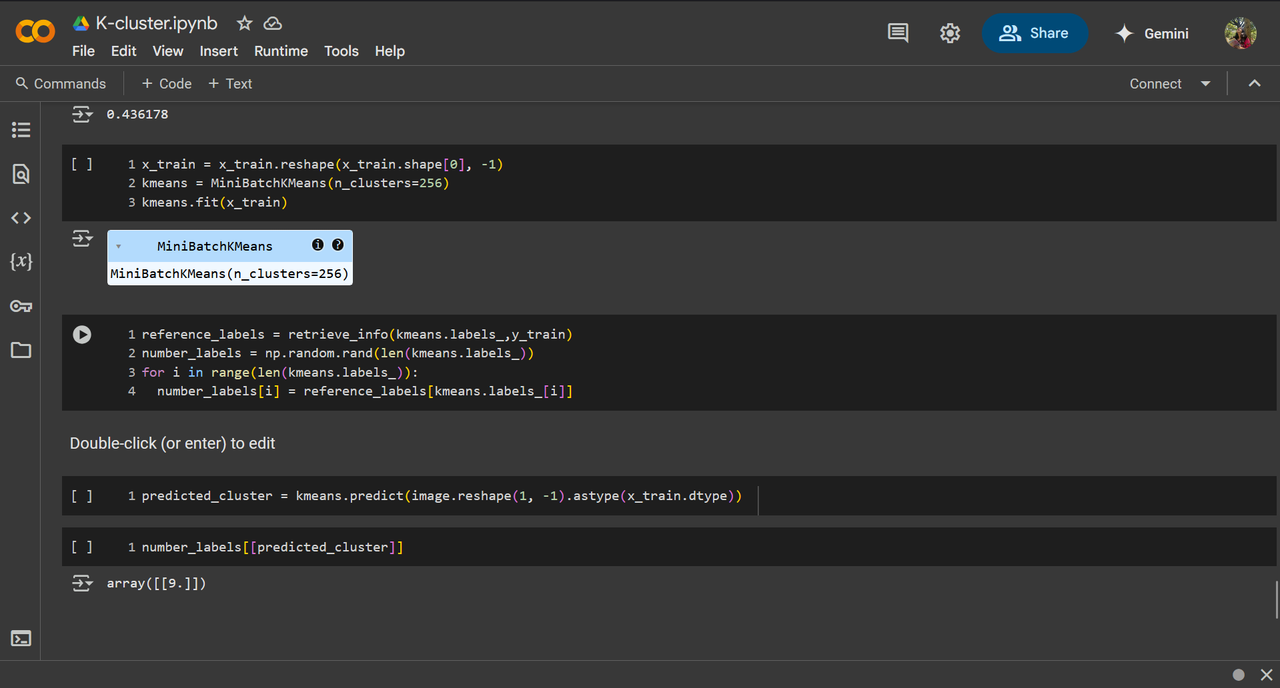 It correctly detected 9!
It correctly detected 9!
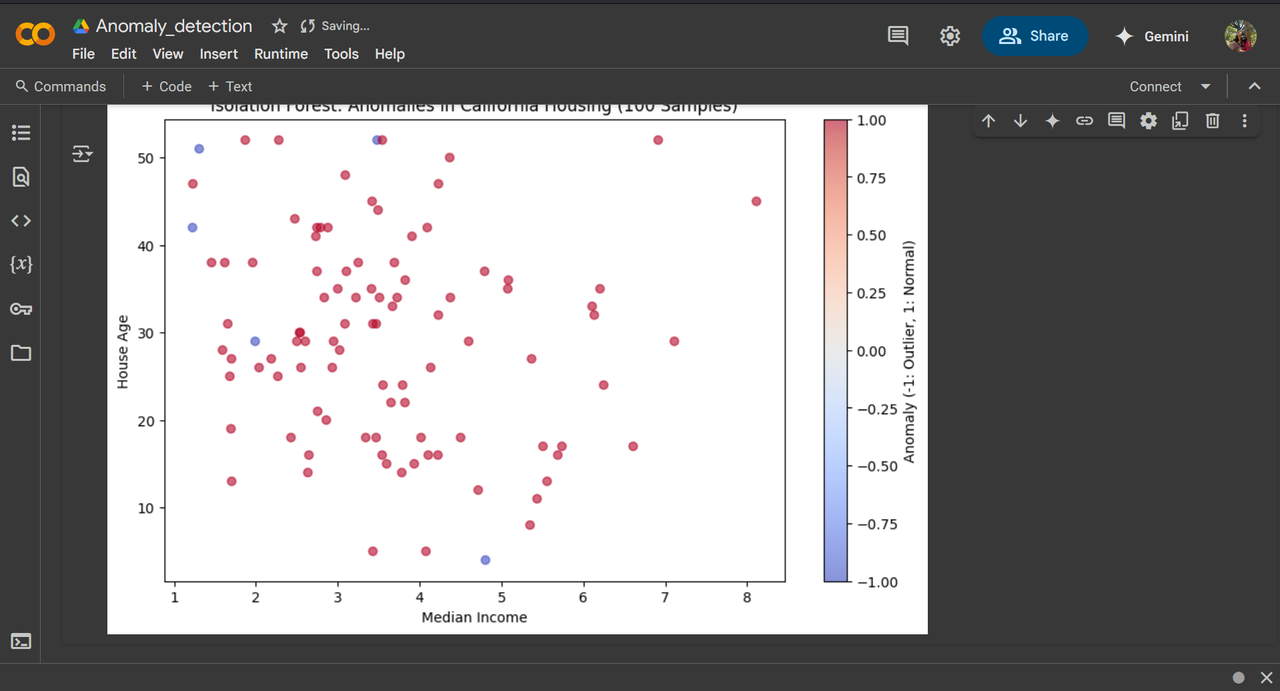
Task 7: Anomaly Detection
Anomaly detection is the process of identifying rare or unusual patterns in data that do not conform to expected behavior. It is widely used in fraud detection, network security, industrial monitoring and healthcare.
I've used LOF, Isolation Forest, one class SVM and Elliptic Envelope. using the contamination parameter, we can obtain different number of anomalies in given data.
Task 8: Generative AI Task Using GAN
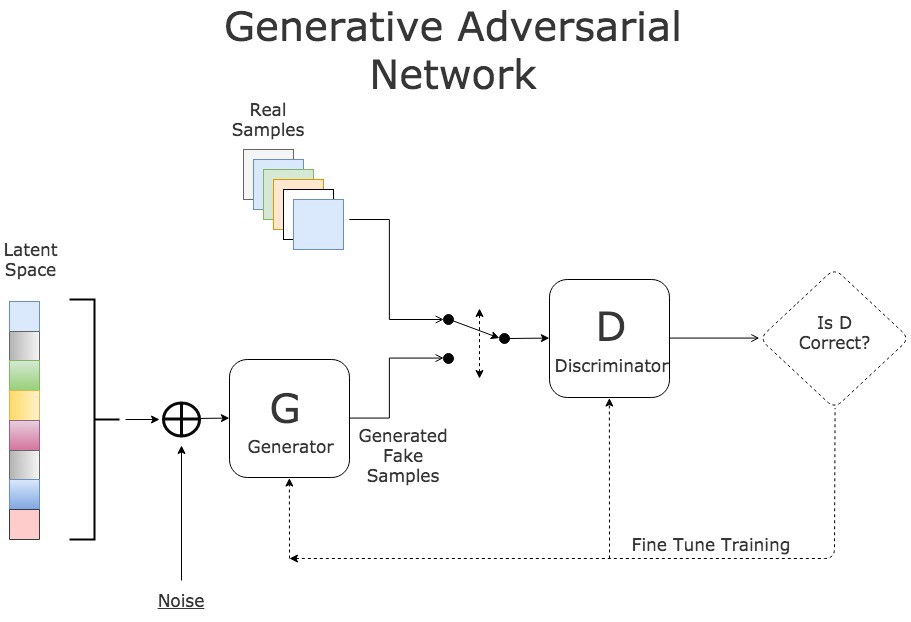 Generative: Generates new Images/video/data.
Generative: Generates new Images/video/data.
Adversarial: The 2 components Generator and Discriminator works against each other. While generator is an artist who creates fake images from random seed(i.e random vector) and tries to convince the discriminator, the detective that the fake image is real. If the discriminator detects the fake image generated by generator , the generator gets a feedback to refine itself until to the point that the discriminator cannot spot the fake ones.
Networks: The 2 networks are Generative and Discriminator
In this code, I've used Binary Cross-Entropy Loss.
Discriminator Loss → How well it detects real vs. fake
Generator Loss → How well it fools the Discriminator.
In this I've used TensorFlow , an open-source deep learning framework and keras - api used to build neural networks. LeakyReLU (Leaky Rectified Linear Unit) is an activation function used in deep networks.
I've used dataset and reduced the dataset to, I've set to 15 epochs as my system could support effectively till that and hence the image quality is not that good. the more number of epochs, the better quality of generated image.
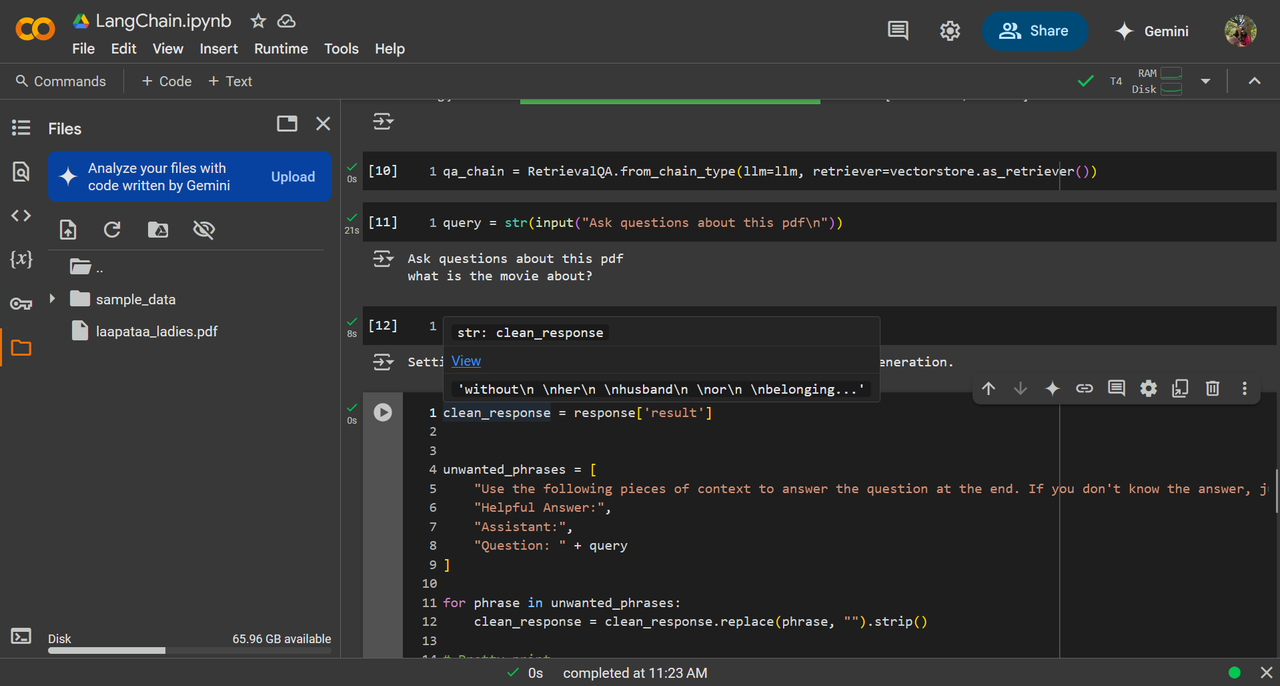
Task 9: PDF Query Using LangChain
LangChain is a framework( for python& JS) to create applications using LLMs. It enables us to easily connect with various models and the chain part connects multiple prompts, LLM calls, or tools into a structured workflow to give us the required response. I have used Microsoft's Phi as it is lightweight and powerful.
- Embedding : a way of converting text into numerical vectors so that a machine can understand and process them. It's kinda like a co-ordinate to understand the relevancy as well as semantic meaning of words. eg: apple and orange (here fruits); apple and Microsoft(here companies)
- Vector Store is used to store and retrieve Embedding Vectors. I have used FAISS((Facebook AI Similarity Search) which is open source and works fast locally.
- It is an instance of RAG(Retrieval-Augmented Generation) : basically AI with external knowledge i.e RAG retrieved data from PDF to LLM which in turn uses this data to provide a response. The user can ask any query to obtain information on the uploaded PDF.
Task 10: Table Analysis Using PaddleOCR
PaddleOCR is a Optical Character Recognition tool and it's open source as well as light weight with multiple features such as multi-language support and more. It provides text detection(using DBNet), Text recognition (using CRNN model), text direction classification( i.e orientation of the text) as well as layout analysis.
In this task, I developed a pipeline to extract data from tabular images and to perform statistical analysis as well as data visualization.
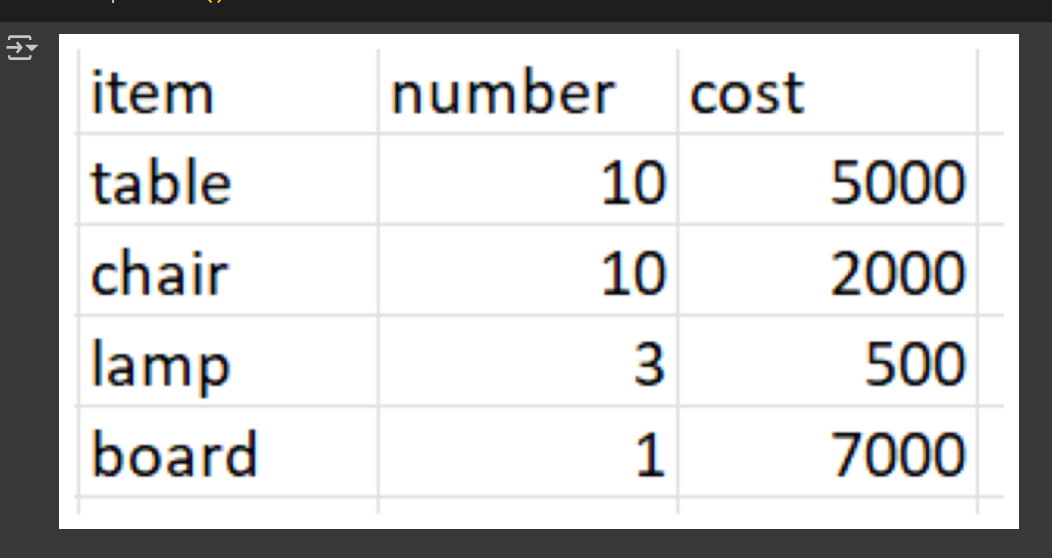
This is the tabular image that was used.
 This image is loaded and slightly processed by OpenCV. PaddleOCR is then initialized and run on the image, the extracted words are put into an array and then using a loop, the words are put under their respective headers. Pandas is used here for converting strings into intergers for further data manipulation.
This image is loaded and slightly processed by OpenCV. PaddleOCR is then initialized and run on the image, the extracted words are put into an array and then using a loop, the words are put under their respective headers. Pandas is used here for converting strings into intergers for further data manipulation.
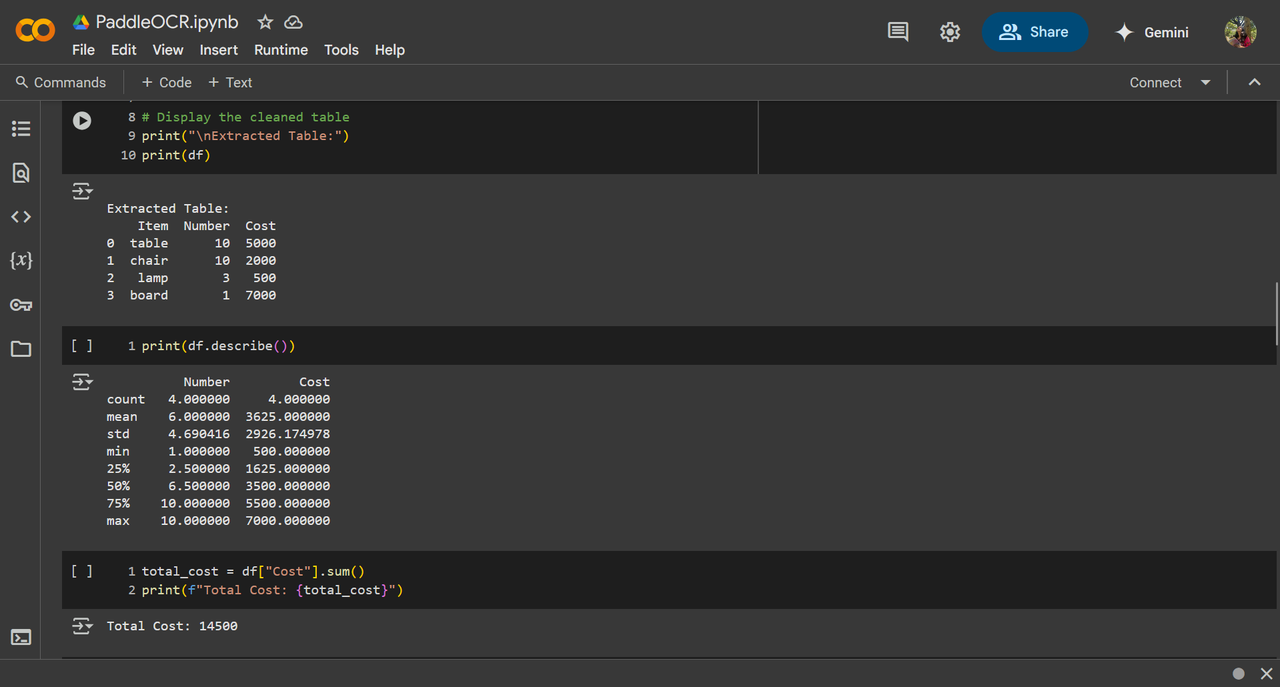
Resulting EXTRACTED TABLE and statistical analysis:
found this article useful in understanding how paddleOCR works