
14 / 9 / 2023
TASK 1:
LINEAR REGRESSION FOR REAL ESTATE PRICES:
Linear regression is a fundamental statistical method used for modeling the relationship between a dependent variable and one or more independent variables. It assumes that this relationship is linear,; meaning that changes in the independent variables lead to proportional changes in the dependent variable. The model aims to find the best-fit line that minimizes the sum of squared differences between predicted and actual values. Linear regression is widely applied in various fields,; including economics,; finance,; and science,; to make predictions,; understand correlations,; and infer causal relationships. It serves as a basis for more complex regression techniques and is a valuable tool in data analysis and machine learning. CALIFORNIA DATASET BENGALURU DATA SET
LOGISTIC REGRESSION ON IRIS DATASET:
Logistic regression is a statistical method used for binary classification tasks,; where the goal is to predict one of two possible outcomes. Unlike linear regression,; it employs the logistic function (sigmoid) to model the probability of the dependent variable belonging to a particular class. It's widely used in fields like healthcare (disease prediction),; marketing (customer churn),; and natural language processing (spam detection). Logistic regression provides interpretable coefficients,; quantifies the strength and direction of feature relationships,; and serves as the foundation for more advanced classification algorithms like support vector machines and neural networks,; making it a crucial tool in predictive modeling and machine learning IRIS CLASSIFICATION
TASK 2:Data visualization using Matplotlib
Matplotlib is a powerful technique for creating a wide range of graphical representations from data. Matplotlib is a popular Python library that offers flexibility and customization in producing plots and charts. With Matplotlib,; you can create line plots,; scatter plots,; bar charts,; histograms,; heatmaps,; and more. It provides fine-grained control over plot elements,; such as labels,; titles,; colors,; and axes,; allowing users to tailor visualizations to their specific needs. Matplotlib can be used for exploratory data analysis,; presenting findings,; and conveying complex information in an understandable manner. PLOTS
TASK 3:
Regression Metrics
Mean Squared Error (MSE)
Mean squared error is perhaps the most popular metric used for regression problems. It essentially finds the average of the squared difference between the target value and the value predicted by the regression model.
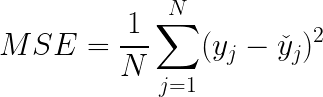
mse = (y-y_hat)**2 print(f\MSE: {mse.mean():0.2f} (+/- {mse.std():0.2f})")
Mean Absolute Error (MAE)
Mean Absolute Error is the average of the difference between the ground truth and the predicted values. Mathematically,; its represented as
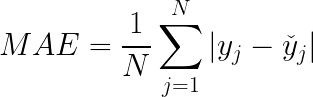
R² Coefficient of determination
R² Coefficient of determination is a metric that’s calculated using other metrics.

 it calculates "How much (what %) of the total variation in Y(target) is explained by the variation in X(regression line)"
it calculates "How much (what %) of the total variation in Y(target) is explained by the variation in X(regression line)"
Accuracy
It is defined as the number of correct predictions divided by the total number of predictions,; multiplied by 100.
from sklearn.metrics import accuracy_score print(f'Accuracy Score is {accuracy_score(y_tes _hat)}')
Confusion Matrix
Confusion Matrix is a tabular visualization of the ground-truth labels versus model predictions. Each row of the confusion matrix represents the instances in a predicted class and each column represents the instances in an actual class. Confusion Matrix is not exactly a performance metric but sort of a basis on which other metrics evaluate the results.

Precision:
Precision is the ratio of true positives and total positives predicted:

TASK 4:
LINEAR REGRESSION FROM SCRATCH LINEAR REGRESSION USING ALGORITHM LOGISTIC REGRESSION USING ALGORITHM LOGISTIC REGRESSION FROM SCRATCH
TASK 5:
K-Nearest Neighbors (KNN) is a supervised machine learning algorithm used for classification and regression tasks. It relies on proximity-based prediction,; assuming that data points with similar features are likely to have similar outcomes. KNN stores the entire training dataset and,; when given a new data point,; calculates the distances to its k-nearest neighbors. For classification,; it assigns the majority class among these neighbors to the new point,; while for regression,; it computes the average of their target values. KNN is intuitive and easy to implement,; making it a versatile choice for various applications,; but selecting an appropriate 'k' value is crucial for its effectiveness. knn from scratch and using algothim
TASK 6:
LINK TO BLOG ON NEURAL NETWORKS
What are Large Language Models and How to Build GPT-4
Large language models are deep learning algorithms that can perform a variety of natural language processing tasks,; such as text generation,; machine translation,; summarization,; question answering,; and more. They use models,; which are neural networks that can process sequential data,; such as text or speech. It allows the model to focus on the most relevant parts of the input and output sequences,; and to learn long-range dependencies between them. LLMs are trained using massive datasets,; mostly scraped from the Internet,; that contain billions or trillions of words. By learning from such large amounts of data,; LLMs can acquire general knowledge about the world,; language,; and various domains. They can also generate fluent and coherent texts that can mimic different styles,; tones,; and formats. One of the most advanced LLMs is GPT-4. GPT-4 is a multimodal model,; which means it can accept both image and text inputs and emit text outputs. It has 175 billion parameters,; which are the numerical values that determine how the model processes the data. GPT-4 is trained using self-supervised learning,; which means it learns from its own data without any human labels or guidance. The main objective of GPT-4 is to predict the next word or token given a sequence of previous words or tokens. This way,; it can generate texts on any topic or task,; given a suitable prompt or instruction.
How to Build GPT-4
Building GPT-4 requires a lot of resources and expertise. Here are some of the main steps involved: Generative pretraining: The first step is to collect and preprocess a large and diverse dataset that covers as many domains and languages as possible. The dataset should also be filtered to remove any harmful or inappropriate content,; The data should then be tokenized,; which means splitting it into smaller units,; that can be represented by numerical values. The model is then trained on this dataset using an auto-regressive objective,; which means it tries to predict the next token given the previous tokens. This way,; the model learns to generate texts that follow the data distribution and capture general linguistic patterns. Supervised fine-tuning: The next step is to adapt the pre-trained model to a specific downstream task using labeled data. For example,; if the task is to classify movie reviews into positive or negative sentiments,; the labeled data would consist of pairs of movie reviews and their corresponding sentiments. The model is then fine-tuned on this data using a supervised learning objective,; which means it tries to predict the correct label given the input text. This way,; the model learns to perform well on the specific task by adjusting its parameters according to the task-specific data and feedback. Reinforcement learning from human feedback: The final step is to improve the model’s performance and alignment with human values using human feedback. For example,; if the task is to generate stories based on user prompts,; the human feedback would consist of ratings or comments on the quality and relevance of the generated stories. The model is then trained using a reinforcement learning objective,; which means it tries to generate texts that maximize the human feedback score. This way,; the model learns to generate texts that are more engaging,; creative,; and ethical by incorporating human preferences and values. Building GPT-4 is not an mammoth task,; but it is an exciting one that can have many benefits for society and humanity. However,; it also comes with many challenges and risks. it is necessary to collaborate with other researchers,; developers,; users,; and stakeholders to ensure the model is used for good purposes and aligned with our goals and values.
TASK 7:
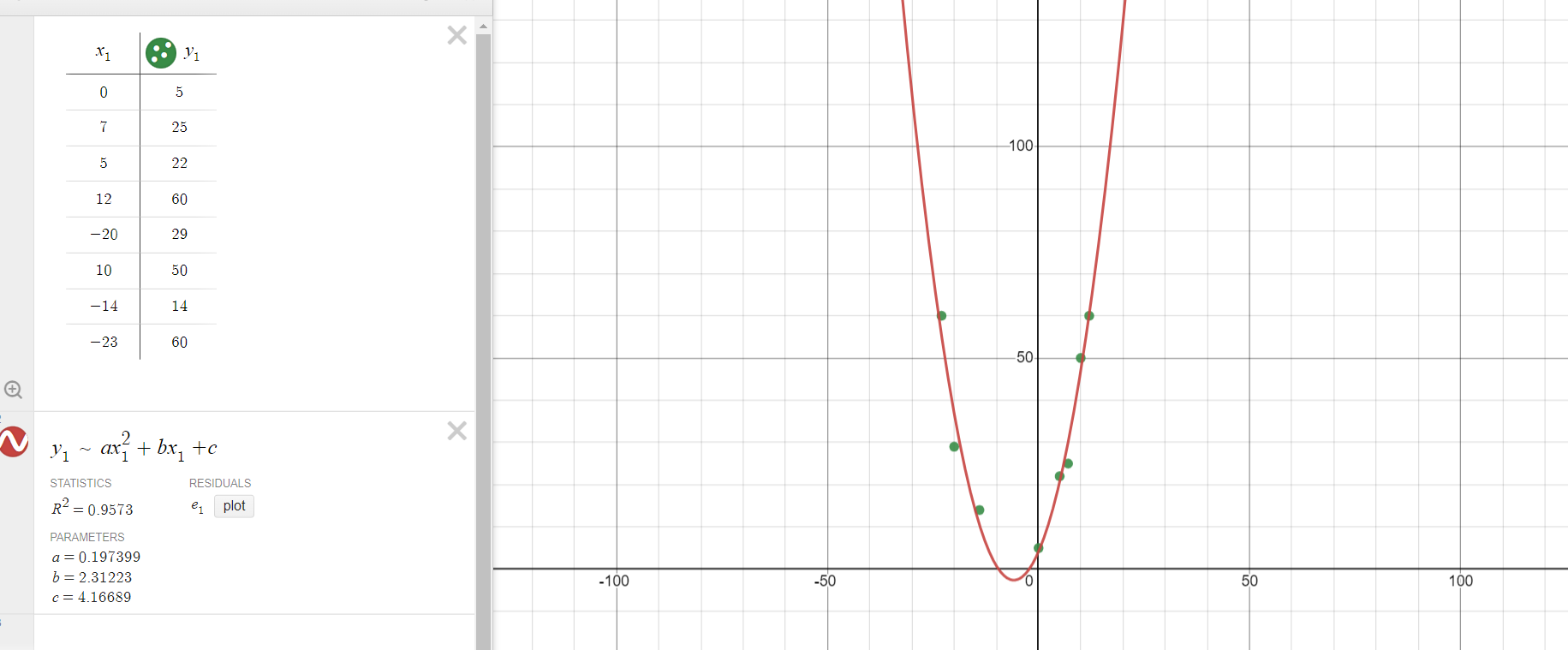
curve fitting using desmos
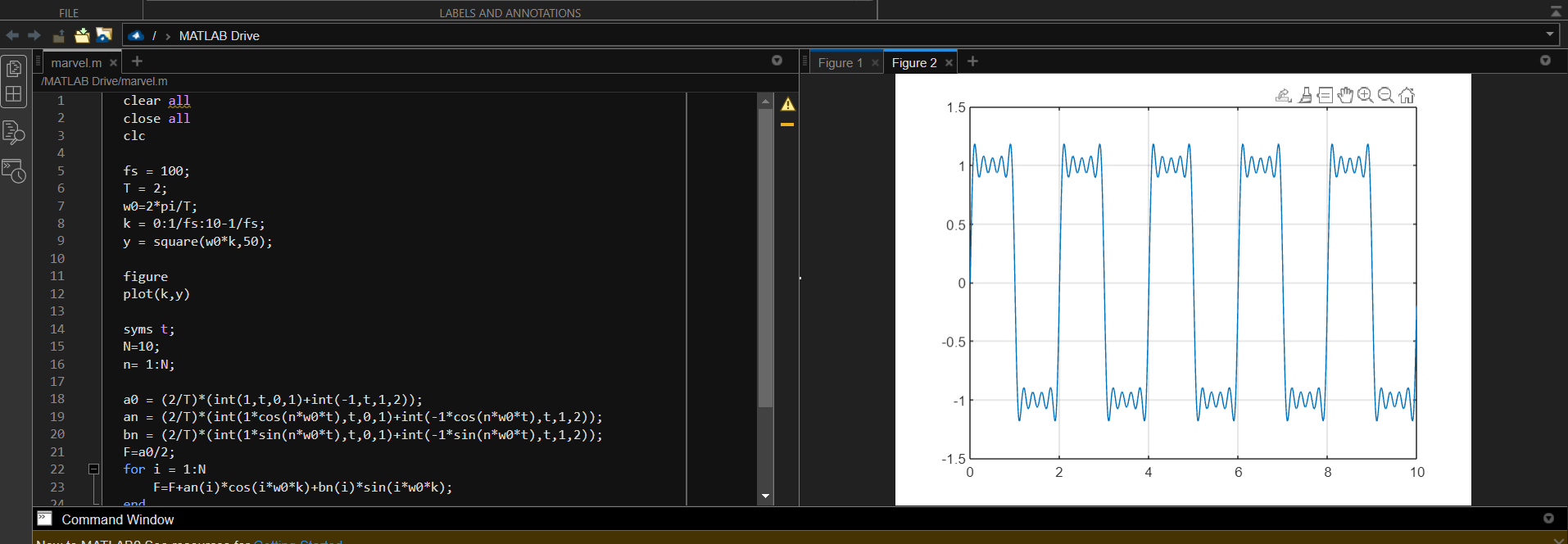
fourier series in matlab
TASK 8:
Data Visualization for Exploratory Data Analysis:
CODE FOR PLOTLY FILES
.png?raw=true)
.png?raw=true)
.png?raw=true)
.png?raw=true) 3D PLOT FILE
BAR PLOT FILE
PIE PLOT FILE
SUNBURST FILE
3D PLOT FILE
BAR PLOT FILE
PIE PLOT FILE
SUNBURST FILE
TASK 9:
A decision tree is a flowchart-like tree structure used in supervised learning algorithms for both classification and regression tasks It is constructed by recursively splitting the training data into subsets based on the values of the attributes until a stopping criterion is met,; such as the maximum depth of the tree or the minimum number of samples required to split a node During training,; the Decision Tree algorithm selects the best attribute to split the data based on a metric such as entropy or Gini impurity,; which measures the level of impurity or randomness in the subsets Decision trees are able to handle both continuous and categorical variables Decision trees are used in many fields,; such as finance,; medicine,; and marketing
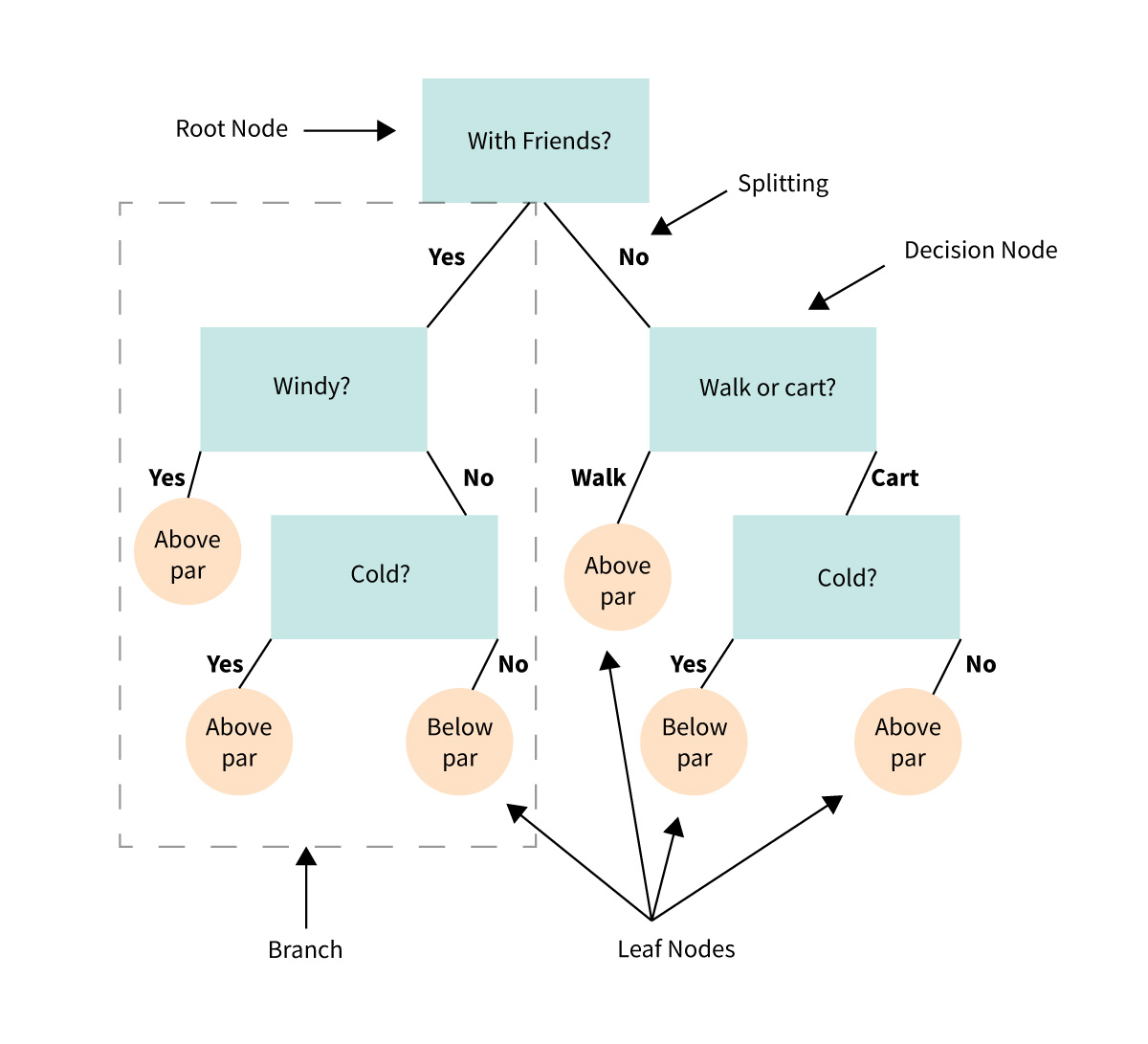 DECISION TREE ON TITANIC DATA SET
DECISION TREE ON TITANIC DATA SET
TASK 10:
EXPLORATION OF A REAL WORLD APPLICATION OF MACHINE LEARNING.
DEEPFAKES
LINK TO CASE STUDY MY DEEP FAKE: <iframe height=""692""> DEEPFAKE 2:<iframe height=""720""> "