
In the late 1980s, neural networks became a prevalent topic in the area of Machine Learning (ML) as well as Artificial Intelligence (AI), due to the invention of various efficient learning methods and network structures. Multilayer perceptron networks trained by “Backpropagation” type algorithms, self-organizing maps, and radial basis function networks were such innovative methods. While neural networks are successfully used in many applications, the interest in researching this topic decreased later on. After that, in 2006, “Deep Learning” (DL) was introduced by Hinton et al., which was based on the concept of artificial neural network (ANN). Deep learning became a prominent topic after that, resulting in a rebirth in neural network research, hence, some times referred to as “new-generation neural networks”. This is because deep networks, when properly trained, have produced significant success in a variety of classification and regression challenges. DL technology is considered as one of the hot topics within the area of machine learning, artificial intelligence as well as data science and analytics, due to its learning capabilities from the given data.
Why Deep Learning in Today’s Research and Applications?
The main focus of today’s Fourth Industrial Revolution (Industry 4.0) is typically technology-driven automation, smart and intelligent systems, in various application areas including smart healthcare, business intelligence, smart cities, cybersecurity intelligence, and many more. Deep learning approaches have grown dramatically in terms of performance in a wide range of applications considering security technologies, particularly, as an excellent solution for uncovering complex architecture in high-dimensional data. Thus, DL techniques can play a key role in building intelligent data-driven systems according to today’s needs, because of their excellent learning capabilities from historical data. Consequently, DL can change the world as well as humans’ everyday life through its automation power and learning from experience. DL technology is therefore relevant to artificial intelligence, machine learning and data science with advanced analytics that are well-known areas in computer science, particularly, today’s intelligent computing.
The Position of Deep Learning in AI
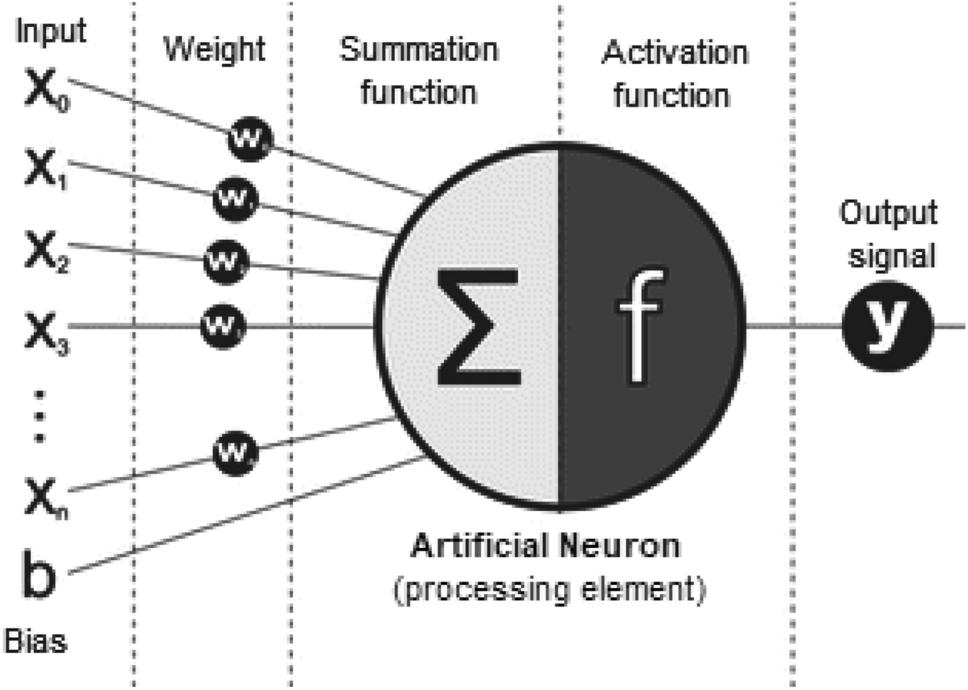
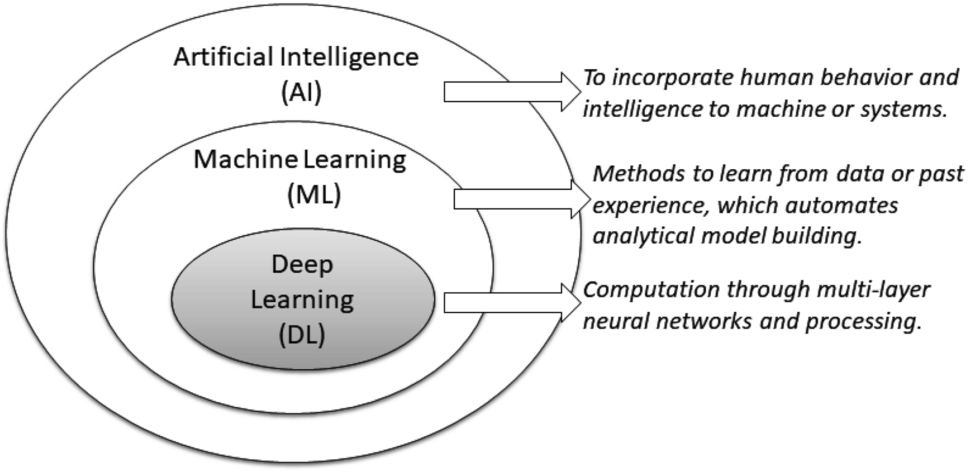
Nowadays, artificial intelligence (AI), machine learning (ML), and deep learning (DL) are three popular terms that are sometimes used interchangeably to describe systems or software that behaves intelligently. In general, AI incorporates human behavior and intelligence to machines or systems, while ML is the method to learn from data or experience, which automates analytical model building. DL also represents learning methods from data where the computation is done through multi-layer neural networks and processing. The term “Deep” in the deep learning methodology refers to the concept of multiple levels or stages through which data is processed for building a data-driven model.
DL Properties and Dependencies
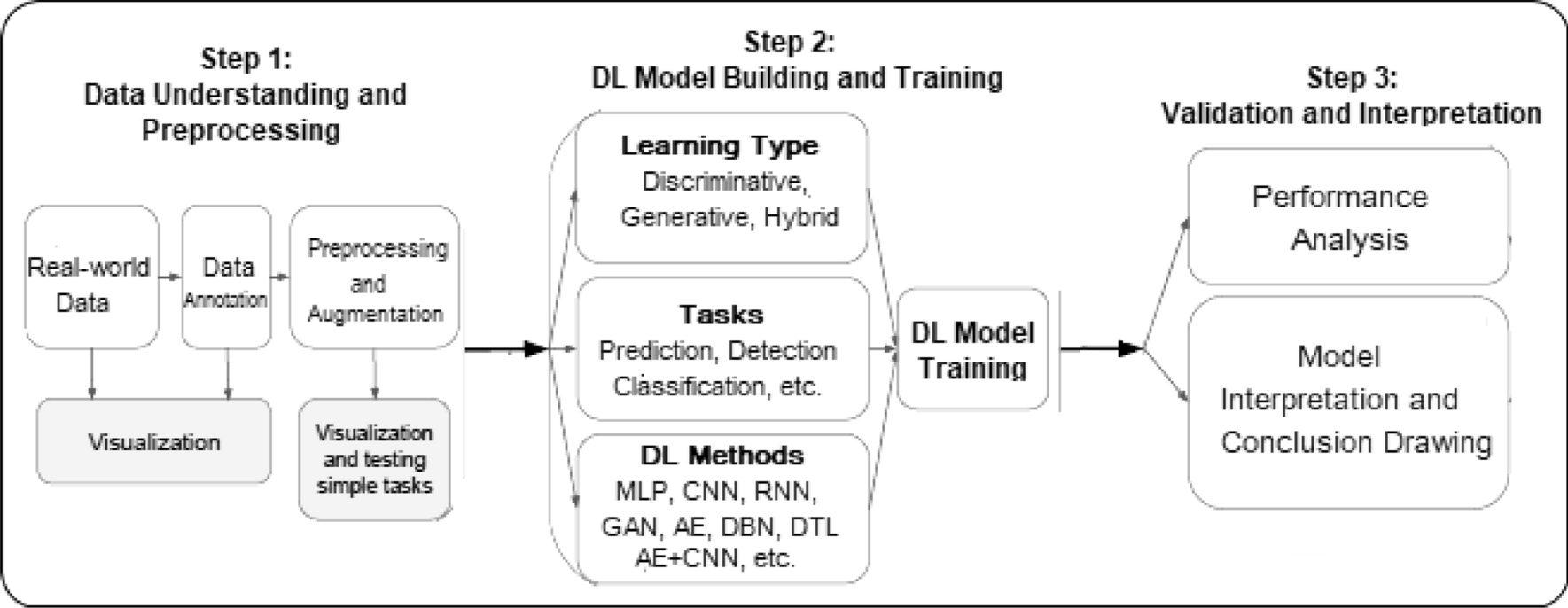
A DL model typically follows the same processing stages as machine learning modeling. It is shown that a deep learning workflow to solve real-world problems, which consists of three processing steps, such as data understanding and preprocessing, DL model building, and training, and validation and interpretation. However, unlike the ML modeling, feature extraction in the DL model is automated rather than manual. K-nearest neighbor, support vector machines, decision tree, random forest, naive Bayes, linear regression, association rules, k-means clustering, are some examples of machine learning techniques that are commonly used in various application areas.
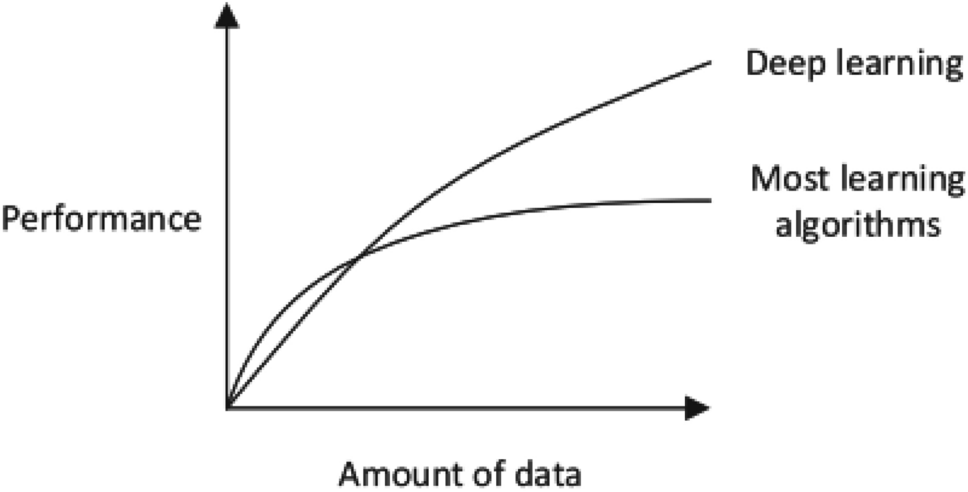
The most significant distinction between deep learning and regular machine learning is how well it performs when data grows exponentially. DL modeling is extremely useful when dealing with a large amount of data because of its capacity to process vast amounts of features to build an effective data-driven model. In terms of developing and training DL models, it relies on parallelized matrix and tensor operations as well as computing gradients and optimization. Several, DL libraries and resources such as PyTorc (with a high-level API called Lightning) and TensorFlow (which also offers Keras as a high-level API) offers these core utilities including many pre-trained models, as well as many other necessary functions for implementation and DL model building.
Deep Learning Techniques and Applications
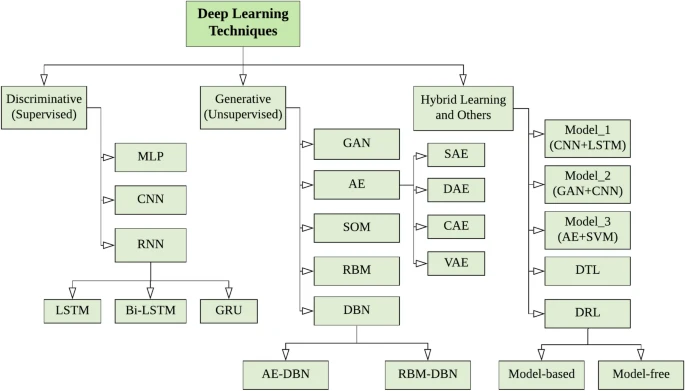 A typical deep neural network contains multiple hidden layers including input and output layers. A taxonomy of DL techniques, broadly divided into three major categories (i) deep networks for supervised or discriminative learning, (ii) deep networks for unsupervised or generative learning, and (ii) deep networks for hybrid learning and relevant others.
A typical deep neural network contains multiple hidden layers including input and output layers. A taxonomy of DL techniques, broadly divided into three major categories (i) deep networks for supervised or discriminative learning, (ii) deep networks for unsupervised or generative learning, and (ii) deep networks for hybrid learning and relevant others.
Deep Networks for Supervised or Discriminative Learning
This category of DL techniques is utilized to provide a discriminative function in supervised or classification applications. Discriminative deep architectures are typically designed to give discriminative power for pattern classification by describing the posterior distributions of classes conditioned on visible data. Discriminative architectures mainly include Multi-Layer Perceptron (MLP), Convolutional Neural Networks (CNN or ConvNet), Recurrent Neural Networks (RNN), along with their variants. In the following, we briefly discuss these techniques.
Multi-layer Perceptron (MLP)
Multi-layer Perceptron (MLP), a supervised learning approach, is a type of feedforward artificial neural network (ANN). It is also known as the foundation architecture of deep neural networks (DNN) or deep learning. A typical MLP is a fully connected network that consists of an input layer that receives input data, an output layer that makes a decision or prediction about the input signal, and one or more hidden layers between these two that are considered as the network’s computational engine. The output of an MLP network is determined using a variety of activation functions, also known as transfer functions, such as ReLU (Rectified Linear Unit), Tanh, Sigmoid, and Softmax . To train MLP employs the most extensively used algorithm “Backpropagation”, a supervised learning technique, which is also known as the most basic building block of a neural network. During the training process, various optimization approaches such as Stochastic Gradient Descent (SGD), Limited Memory BFGS (L-BFGS), and Adaptive Moment Estimation (Adam) are applied. MLP requires tuning of several hyperparameters such as the number of hidden layers, neurons, and iterations, which could make solving a complicated model computationally expensive. However, through partial fit, MLP offers the advantage of learning non-linear models in real-time or online.
Convolutional Neural Network (CNN or ConvNet)
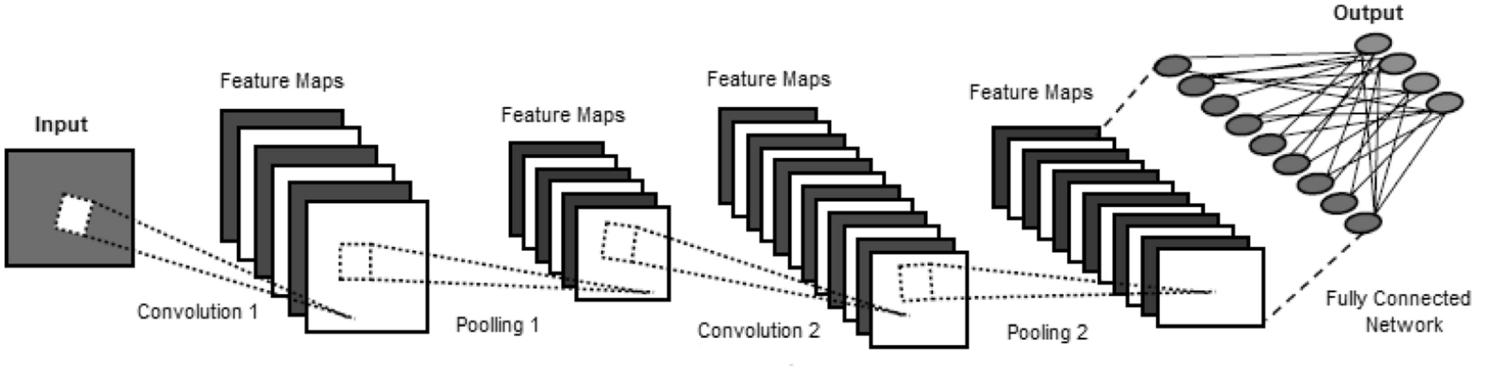
The Convolutional Neural Network (CNN or ConvNet) is a popular discriminative deep learning architecture that learns directly from the input without the need for human feature extraction.Each layer in CNN takes into account optimum parameters for a meaningful output as well as reduces model complexity. CNN also uses a ‘dropout’ that can deal with the problem of over-fitting, which may occur in a traditional network.
Recurrent Neural Network (RNN)
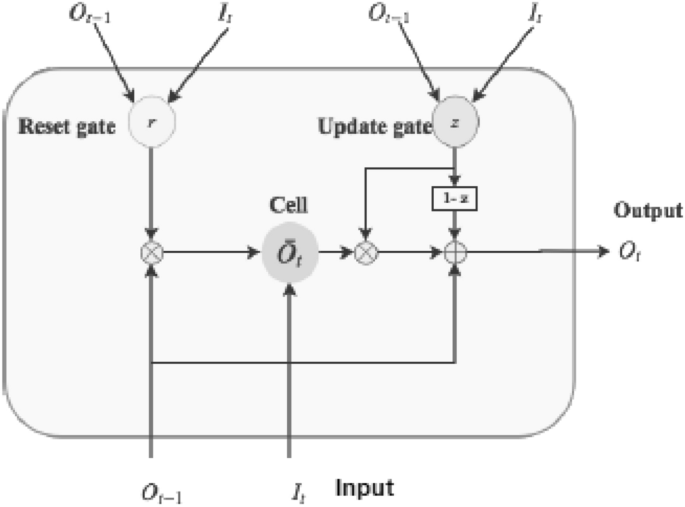
A Recurrent Neural Network (RNN) is another popular neural network, which employs sequential or time-series data and feeds the output from the previous step as input to the current stage. Like feedforward and CNN, recurrent networks learn from training input, however, distinguish by their “memory”, which allows them to impact current input and output through using information from previous inputs. Unlike typical DNN, which assumes that inputs and outputs are independent of one another, the output of RNN is reliant on prior elements within the sequence. However, standard recurrent networks have the issue of vanishing gradients, which makes learning long data sequences challenging.
Deep Networks for Generative or Unsupervised Learning
This category of DL techniques is typically used to characterize the high-order correlation properties or features for pattern analysis or synthesis, as well as the joint statistical distributions of the visible data and their associated classes. The key idea of generative deep architectures is that during the learning process, precise supervisory information such as target class labels is not of concern. As a result, the methods under this category are essentially applied for unsupervised learning as the methods are typically used for feature learning or data generating and representation. Thus, generative modeling can be used as preprocessing for the supervised learning tasks as well, which ensures the discriminative model accuracy. Commonly used deep neural network techniques for unsupervised or generative learning are Generative Adversarial Network (GAN), Autoencoder (AE), Restricted Boltzmann Machine (RBM), Self-Organizing Map (SOM), and Deep Belief Network (DBN) along with their variants.
Generative Adversarial Network (GAN)
A Generative Adversarial Network (GAN), designed by Ian Goodfellow, is a type of neural network architecture for generative modeling to create new plausible samples on demand. It involves automatically discovering and learning regularities or patterns in input data so that the model may be used to generate or output new examples from the original dataset. Thus in GAN modeling, both the generator and discriminator are trained to compete with each other. While the generator tries to fool and confuse the discriminator by creating more realistic data, the discriminator tries to distinguish the genuine data from the fake data generated by G.
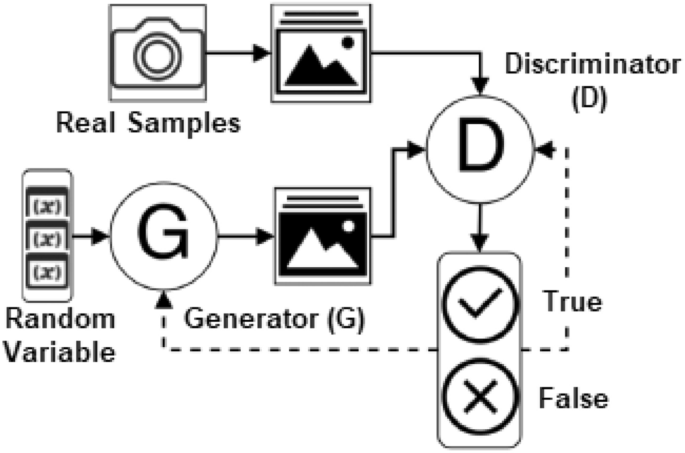
Auto-Encoder (AE)
An auto-encoder (AE) is a popular unsupervised learning technique in which neural networks are used to learn representations. Typically, auto-encoders are used to work with high-dimensional data, and dimensionality reduction explains how a set of data is represented. Encoder, code, and decoder are the three parts of an autoencoder. The encoder compresses the input and generates the code, which the decoder subsequently uses to reconstruct the input. The AEs have recently been used to learn generative data models. The auto-encoder is widely used in many unsupervised learning tasks, e.g., dimensionality reduction, feature extraction, efficient coding, generative modeling, denoising, anomaly or outlier detection, etc. Principal component analysis (PCA), which is also used to reduce the dimensionality of huge data sets, is essentially similar to a single-layered AE with a linear activation function. Regularized autoencoders such as sparse, denoising, and contractive are useful for learning representations for later classification tasks, while variational autoencoders can be used as generative models, discussed below.
Research Directions and Future Aspects
- Automation in Data Annotation
- Data Preparation for Ensuring Data Quality
- Black-box Perception and Proper DL/ML Algorithm Selection
- Deep Networks for Supervised or Discriminative Learning
- Deep Networks for Unsupervised or Generative Learning
- Hybrid/Ensemble Modeling and Uncertainty Handling
- Dynamism in Selecting Threshold/ Hyper-parameters Values, and Network Structures with Computational Efficiency
- Lightweight Deep Learning Modeling for Next-Generation Smart Devices and Applications
- Incorporating Domain Knowledge into Deep Learning Modeling
- Designing General Deep Learning Framework for Target Application Domains
Conclusion
Deep learning, unlike traditional machine learning and data mining algorithms, can produce extremely high-level data representations from enormous amounts of raw data. As a result, it has provided an excellent solution to a variety of real-world problems. A successful deep learning technique must possess the relevant data-driven modeling depending on the characteristics of raw data. The sophisticated learning algorithms then need to be trained through the collected data and knowledge related to the target application before the system can assist with intelligent decision-making. Deep learning has shown to be useful in a wide range of applications and research areas such as healthcare, sentiment analysis, visual recognition, business intelligence, cybersecurity, and many more.