
BLOG · 31/1/2026
MARVEL LEVEL 2 Report

Marvel Level 2 Task Report
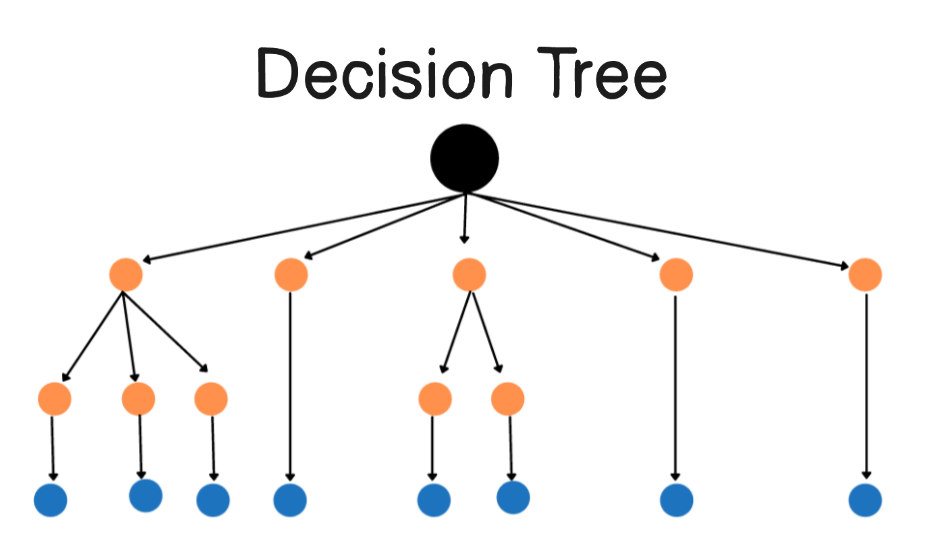
Task - 1 : Decision Tree based ID3 Algorithm
Decision tree was one of the most easy task to comprehend as it is based of on a simple condition of yes or no and the filteration follows and arrives to a conclusive result . ID3 (Iterative Dichotomiser 3) is a decision tree algorithm that builds a tree top-down using Entropy and Information Gain.
For this task I used a dataset based on Vehicle sales and the most likely information of battery health was chosen as the factor of information gain


https://github.com/Avantikalal5805/Marvel-level-2/blob/main/LVL2%20TASK%201%20(1).ipynb
Task -2 : Naive Bayesian Classifier
Probability plays an important role in prediction of model and has its own set of assumptions which leads us to find the class with highest predictiblity
Import libraries and load the dataset.
Preprocess data (cleaning, encoding, etc.).
Split data into train and test sets.
Train a Naive Bayes model
Evaluate model performance
Test on unseen data.
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/Naives%20bayes.ipynb
Task -3 : Ensemble Techniques
It was one of my most favourite task as for this task , we had to find the best machine learning model like KNN , SVM , Linear regression and it is tested on training model and the weighed accuracy of all the models applied are averaged and the best model for the model is formed
. By aggregating the predictions of several base models, ensemble methods reduce variance, bias, or improve prediction accuracy. They are particularly effective in handling complex datasets and improving model robustness. Common ensemble methods include Bagging , Stacking and boosting.
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/Level%202%20-%20task%203.ipynb
Task -4 : Random Forest, GBM and Xgboost
Random Forest: An ensemble learning method that constructs multiple decision trees and combines their outputs to improve accuracy and reduce overfitting.
GBM (Gradient Boosting Machine): A boosting algorithm that builds trees sequentially, each correcting the errors of the previous ones by minimizing a loss function.
XGBoost (Extreme Gradient Boosting): An optimized version of GBM that uses regularization, parallel processing, and efficient handling of missing values for better speed and performance.
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/RANDOM%20FOREST%20.ipynb
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/XGB.ipynb
Task-5: Hyperparameter Tuning
Hyperparameter tuning is the process of optimizing model settings (hyperparameters) that are not learned from data, to improve a machine learning model's performance.
It is basically a way of choosing the best setting for a machine learning model before running it on a training set so that it gives the best performance
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/hyperparameter%20.ipynb
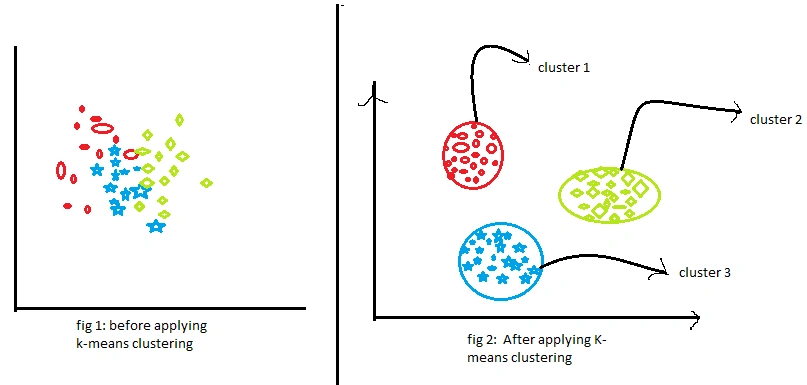
Task- 6 : Image Classification using KMeans Clustering
Kmeans clustering was personally very fascinating to me as the images from being massive was clustered down to the smallest pixels for analysing , From uploading images to then converting images to features and scaling them
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/KNN%20IMAGE%20CLUSTER%20.ipynb
Task-7:Anomaly Detection
.jpg)
Datas have sometimes an error which can be found out using detection where the values is set for each variables and the training set when runs , the anomaly is detected as it is a distinct drift.
Import libraries and load the dataset.
Preprocess data (normalize, clean, etc.).
Choose an anomaly detection algorithm.
Train the model on the dataset.
Evaluate results by identifying anomalies.
Visualize anomalies using scatter plots or other graphs.
.jpg)
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/Anomaly%20detection.ipynb
Task-8: Generative AI Task Using GAN
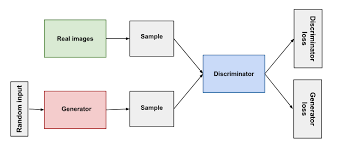
This task was a challenging one as it had to interpret and generate the image and also have a detection in the same dataset to classify it as a real or fake picture . In an AIML language - a generator that creates realistic data and a discriminator that distinguishes real from fake data .
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/GAN.ipynb
Task-9: PDF Query Using LangChain
A PDF query system built using LangChain works by first reading and extracting text from a PDF document. This extracted text is then broken into smaller chunks so that it can be processed and searched more effectively.I used google colab for this task for better capacity of storage which it can run thought the image was a little blurry
STEPS
Extract Text: Read and extract text from a PDF file using a library like PyMuPDF or pdfplumber.
Split & Process Text: Divide extracted text into manageable chunks for better querying.
Embed Text: Convert text into vector embeddings using a model like OpenAI
Store in Vector Database: Save embeddings in a vector store (e.g., FAISS) for retrieval.
Query Processing: Accept user queries and convert them into vector representations.
Retrieve Relevant Sections: Search the vector database for the most relevant text chunks.
Generate Response: Use an LLM (like OpenAI) to generate human-like answers from retrieved data.
https://github.com/Avantikalal5805/Marvel-level-2/blob/main/PDFQuery_Langchain.ipynb
Task-10: Table Analysis Using PaddleOCR
Though I plan on completing the task with better understanding, so far I have understood PaddleOCR is an open-source Optical Character Recognition (OCR) tool based on PaddlePaddle, designed for extracting text from images or scanned documents. It supports multiple languages, handles complex layouts, and provides high accuracy for text detection and recognition.