
BLOG · 22/5/2024
What lies below the hood of LLM ?
Large language models basics!
 | OP |
Large Language Model
In brief:
Large Language models are models that use a transformer to take some input prompt and tokenize the words. Based on the tokenization, they convert the words into vectors, by which the transformer can predict what the next word will be or what is most likely being conveyed.
Nooo, it's not this kind of transformer!
![]()
No, not this one either!
Now you might be wondering, "Wow, this new technology is so fascinating!" Truth be told, even I was shocked to hear that these transformers have been used for years, and we have been using one named BERT for a long time. This is the transformer Google uses to take the input and then give attention and searches to understand what we mean to say.
Two types of Transformer:
As some people would have noticed, Google's transformer and ChatGPT by OpenAI, the transformers are performing different tasks. They both give attention to input and expand on it, but one generates output based on it, while the other just expands the input and finds relevant topics based on that.
Google's transformer is an encoder that encodes our input, while ChatGPT's is a decoder that encodes and then even provides some output and generates something.
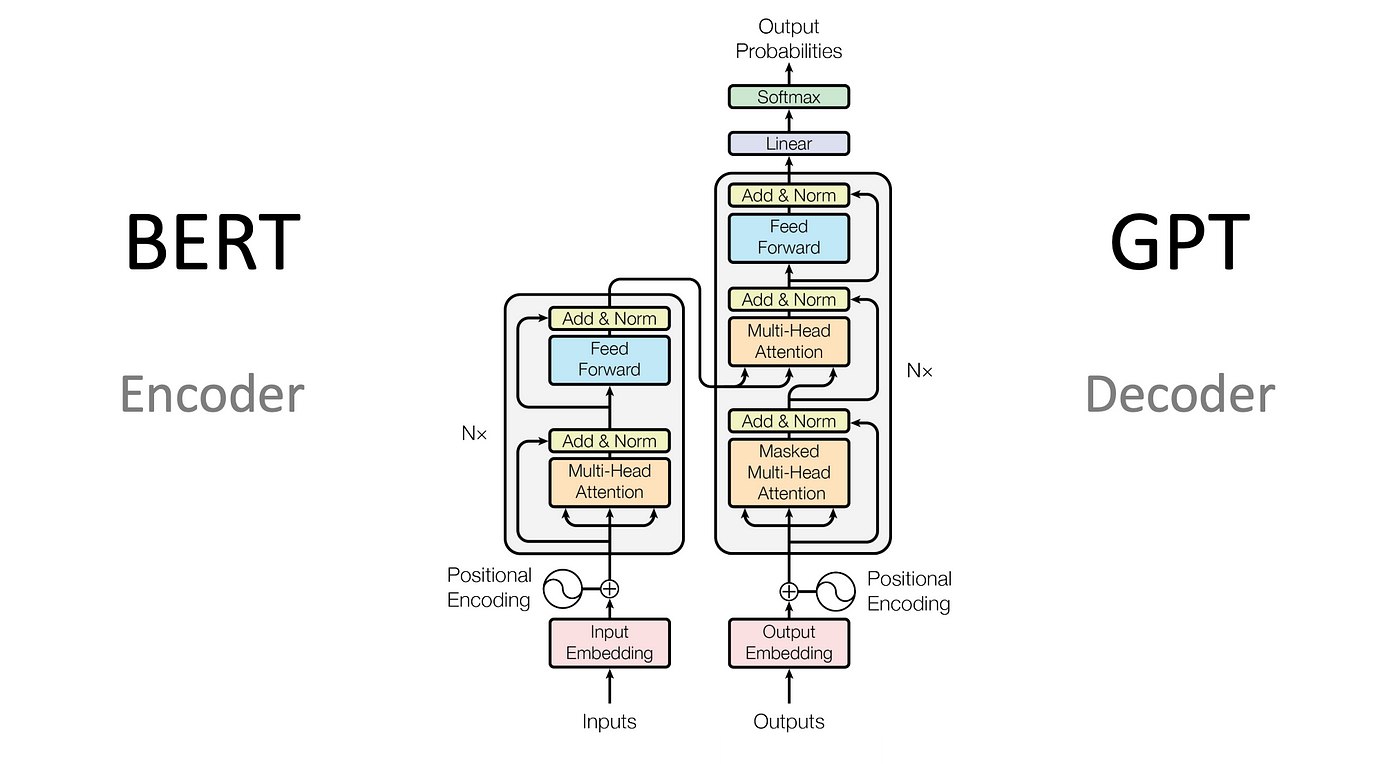
How tokenization works!
Tokenization involves assigning a unique number to each word. For example:
Mr Bank went to the mall
The tokenization will be:
["Mr", "Bank", "went", "to", "the", "mall"]
[1, 2, 6, 7, 8, 25]
This tokenization is already pre-learned by the model.

Let's consider the word "Banks". When we say the word "bank", we typically think of a financial institute. However, in the context of a sentence, it could be a noun (name). The model is fed a large amount of data and tokenizes based on the context and usage. For example, the word "meow" will be highly associated with a cat and not a dog. The model tokenizes based on the association of data.
In case this was a bit complicated, "meow" is associated with a cat and not a dog.
Self-Attention
Yes, the model gives itself attention and weighs the importance of each token. It then assesses the relevance of each token in the sentence. The model consists of multiple layers of self-attention, and they are all feedforward (they provide the data to the forward transformers). Depending on the task, there are some other layers before the output.
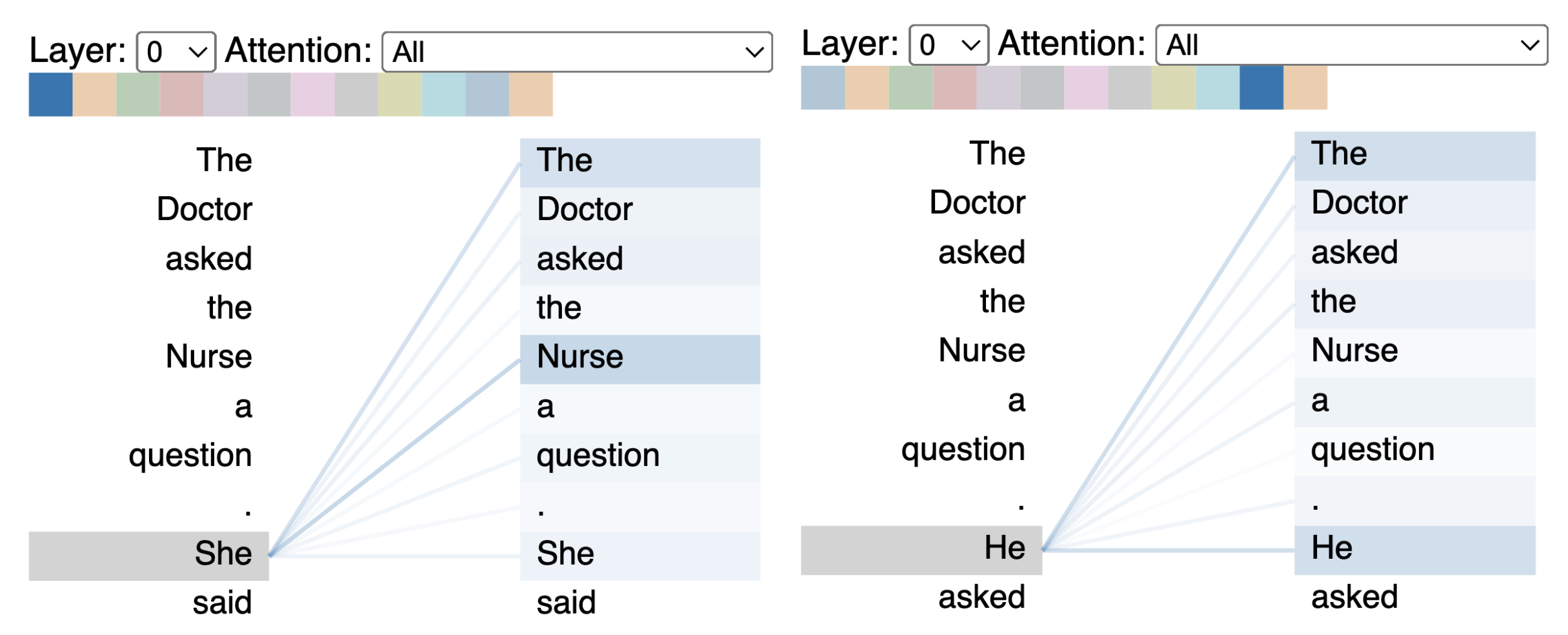
As we can see in the image, when we say "she", then it is being mapped to "the nurse". This way, it maps and understands the context.
This is the basics of how a transformer works and how GPT and other AIs work!
I hope this helped!
Thank you!! Dhruv Mahajan